Machine Learning: VWAP [YinYangAlgorithms]Machine Learning: VWAP aims to use Machine Learning to Identify the best location to Anchor the VWAP at. Rather than using a traditional fixed length or simply adjusting based on a Date / Time; by applying Machine Learning we may hope to identify crucial areas which make sense to reset the VWAP and start anew. VWAP’s may act similar to a Bollinger Band in the sense that they help to identify both Overbought and Oversold Price locations based on previous movements and help to identify how far the price may move within the current Trend. However, unlike Bollinger Bands, VWAPs have the ability to parabolically get quite spaced out and also reset. For this reason, the price may never actually go from the Lower to the Upper and vice versa (when very spaced out; when the Upper and Lower zones are narrow, it may bounce between the two). The reason for this is due to how the anchor location is calculated and in this specific Indicator, how it changes anchors based on price movement calculated within Machine Learning.
This Indicator changes the anchor if the Low < Lowest Low of a length of X and likewise if the High > Highest High of a length of X. This logic is applied within a Machine Learning standpoint that likewise amplifies this Lookback Length by adding a Machine Learning Length to it and increasing the lookback length even further.
Due to how the anchor for this VWAP changes, you may notice that the Basis Line (Orange) may act as a Trend Identifier. When the Price is above the basis line, it may represent a bullish trend; and likewise it may represent a bearish trend when below it. You may also notice what may happen is when the trend occurs, it may push all the way to the Upper or Lower levels of this VWAP. It may then proceed to move horizontally until the VWAP expands more and it may gain more movement; or it may correct back to the Basis Line. If it corrects back to the basis line, what may happen is it either uses the Basis Line as a Support and continues in its current direction, or it will change the VWAP anchor and start anew.
Tutorial:
If we zoom in on the most recent VWAP we can see how it expands. Expansion may be caused by time but generally it may be caused by price movement and volume. Exponential Price movement causes the VWAP to expand, even if there are corrections to it. However, please note Volume adds a large weighted factor to the calculation; hence Volume Weighted Average Price (VWAP).
If you refer to the white circle in the example above; you’ll be able to see that the VWAP expanded even while the price was correcting to the Basis line. This happens due to exponential movement which holds high volume. If you look at the volume below the white circle, you’ll notice it was very large; however even though there was exponential price movement after the white circle, since the volume was low, the VWAP didn’t expand much more than it already had.
There may be times where both Volume and Price movement isn’t significant enough to cause much of an expansion. During this time it may be considered to be in a state of consolidation. While looking at this example, you may also notice the color switch from red to green to red. The color of the VWAP is related to the movement of the Basis line (Orange middle line). When the current basis is > the basis of the previous bar the color of the VWAP is green, and when the current basis is < the basis of the previous bar, the color of the VWAP is red. The color may help you gauge the current directional movement the price is facing within the VWAP.
You may have noticed there are signals within this Indicator. These signals are composed of Green and Red Triangles which represent potential Bullish and Bearish momentum changes. The Momentum changes happen when the Signal Type:
The High/Low or Close (You pick in settings)
Crosses one of the locations within the VWAP.
Bullish Momentum change signals occur when :
Signal Type crosses OVER the Basis
Signal Type crosses OVER the lower level
Bearish Momentum change signals occur when:
Signal Type crosses UNDER the Basis
Signal Type Crosses UNDER the upper level
These signals may represent locations where momentum may occur in the direction of these signals. For these reasons there are also alerts available to be set up for them.
If you refer to the two circles within the example above, you may see that when the close goes above the basis line, how it mat represents bullish momentum. Likewise if it corrects back to the basis and the basis acts as a support, it may continue its bullish momentum back to the upper levels again. However, if you refer to the red circle, you’ll see if the basis fails to act as a support, it may then start to correct all the way to the lower levels, or depending on how expanded the VWAP is, it may just reset its anchor due to such drastic movement.
You also have the ability to disable Machine Learning by setting ‘Machine Learning Type’ to ‘None’. If this is done, it will go off whether you have it set to:
Bullish
Bearish
Neutral
For the type of VWAP you want to see. In this example above we have it set to ‘Bullish’. Non Machine Learning VWAP are still calculated using the same logic of if low < lowest low over length of X and if high > highest high over length of X.
Non Machine Learning VWAP’s change much quicker but may also allow the price to correct from one side to the other without changing VWAP Anchor. They may be useful for breaking up a trend into smaller pieces after momentum may have changed.
Above is an example of how the Non Machine Learning VWAP looks like when in Bearish. As you can see based on if it is Bullish or Bearish is how it favors the trend to be and may likewise dictate when it changes the Anchor.
When set to neutral however, the Anchor may change quite quickly. This results in a still useful VWAP to help dictate possible zones that the price may move within, but they’re also much tighter zones that may not expand the same way.
We will conclude this Tutorial here, hopefully this gives you some insight as to why and how Machine Learning VWAPs may be useful; as well as how to use them.
Settings:
VWAP:
VWAP Type: Type of VWAP. You can favor specific direction changes or let it be Neutral where there is even weight to both. Please note, these do not apply to the Machine Learning VWAP.
Source: VWAP Source. By default VWAP usually uses HLC3; however OHLC4 may help by providing more data.
Lookback Length: The Length of this VWAP when it comes to seeing if the current High > Highest of this length; or if the current Low is < Lowest of this length.
Standard VWAP Multiplier: This multiplier is applied only to the Standard VWMA. This is when 'Machine Learning Type' is set to 'None'.
Machine Learning:
Use Rational Quadratics: Rationalizing our source may be beneficial for usage within ML calculations.
Signal Type: Bullish and Bearish Signals are when the price crosses over/under the basis, as well as the Upper and Lower levels. These may act as indicators to where price movement may occur.
Machine Learning Type: Are we using a Simple ML Average, KNN Mean Average, KNN Exponential Average or None?
KNN Distance Type: We need to check if distance is within the KNN Min/Max distance, which distance checks are we using.
Machine Learning Length: How far back is our Machine Learning going to keep data for.
k-Nearest Neighbour (KNN) Length: How many k-Nearest Neighbours will we account for?
Fast ML Data Length: What is our Fast ML Length? This is used with our Slow Length to create our KNN Distance.
Slow ML Data Length: What is our Slow ML Length? This is used with our Fast Length to create our KNN Distance.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!
Knn

Machine Learning: Optimal RSI [YinYangAlgorithms]This Indicator, will rate multiple different lengths of RSIs to determine which RSI to RSI MA cross produced the highest profit within the lookback span. This ‘Optimal RSI’ is then passed back, and if toggled will then be thrown into a Machine Learning calculation. You have the option to Filter RSI and RSI MA’s within the Machine Learning calculation. What this does is, only other Optimal RSI’s which are in the same bullish or bearish direction (is the RSI above or below the RSI MA) will be added to the calculation.
You can either (by default) use a Simple Average; which is essentially just a Mean of all the Optimal RSI’s with a length of Machine Learning. Or, you can opt to use a k-Nearest Neighbour (KNN) calculation which takes a Fast and Slow Speed. We essentially turn the Optimal RSI into a MA with different lengths and then compare the distance between the two within our KNN Function.
RSI may very well be one of the most used Indicators for identifying crucial Overbought and Oversold locations. Not only that but when it crosses its Moving Average (MA) line it may also indicate good locations to Buy and Sell. Many traders simply use the RSI with the standard length (14), however, does that mean this is the best length?
By using the length of the top performing RSI and then applying some Machine Learning logic to it, we hope to create what may be a more accurate, smooth, optimal, RSI.
Tutorial:
This is a pretty zoomed out Perspective of what the Indicator looks like with its default settings (except with Bollinger Bands and Signals disabled). If you look at the Tables above, you’ll notice, currently the Top Performing RSI Length is 13 with an Optimal Profit % of: 1.00054973. On its default settings, what it does is Scan X amount of RSI Lengths and checks for when the RSI and RSI MA cross each other. It then records the profitability of each cross to identify which length produced the overall highest crossing profitability. Whichever length produces the highest profit is then the RSI length that is used in the plots, until another length takes its place. This may result in what we deem to be the ‘Optimal RSI’ as it is an adaptive RSI which changes based on performance.
In our next example, we changed the ‘Optimal RSI Type’ from ‘All Crossings’ to ‘Extremity Crossings’. If you compare the last two examples to each other, you’ll notice some similarities, but overall they’re quite different. The reason why is, the Optimal RSI is calculated differently. When using ‘All Crossings’ everytime the RSI and RSI MA cross, we evaluate it for profit (short and long). However, with ‘Extremity Crossings’, we only evaluate it when the RSI crosses over the RSI MA and RSI <= 40 or RSI crosses under the RSI MA and RSI >= 60. We conclude the crossing when it crosses back on its opposite of the extremity, and that is how it finds its Optimal RSI.
The way we determine the Optimal RSI is crucial to calculating which length is currently optimal.
In this next example we have zoomed in a bit, and have the full default settings on. Now we have signals (which you can set alerts for), for when the RSI and RSI MA cross (green is bullish and red is bearish). We also have our Optimal RSI Bollinger Bands enabled here too. These bands allow you to see where there may be Support and Resistance within the RSI at levels that aren’t static; such as 30 and 70. The length the RSI Bollinger Bands use is the Optimal RSI Length, allowing it to likewise change in correlation to the Optimal RSI.
In the example above, we’ve zoomed out as far as the Optimal RSI Bollinger Bands go. You’ll notice, the Bollinger Bands may act as Support and Resistance locations within and outside of the RSI Mid zone (30-70). In the next example we will highlight these areas so they may be easier to see.
Circled above, you may see how many times the Optimal RSI faced Support and Resistance locations on the Bollinger Bands. These Bollinger Bands may give a second location for Support and Resistance. The key Support and Resistance may still be the 30/50/70, however the Bollinger Bands allows us to have a more adaptive, moving form of Support and Resistance. This helps to show where it may ‘bounce’ if it surpasses any of the static levels (30/50/70).
Due to the fact that this Indicator may take a long time to execute and it can throw errors for such, we have added a Setting called: Adjust Optimal RSI Lookback and RSI Count. This settings will automatically modify the Optimal RSI Lookback Length and the RSI Count based on the Time Frame you are on and the Bar Indexes that are within. For instance, if we switch to the 1 Hour Time Frame, it will adjust the length from 200->90 and RSI Count from 30->20. If this wasn’t adjusted, the Indicator would Timeout.
You may however, change the Setting ‘Adjust Optimal RSI Lookback and RSI Count’ to ‘Manual’ from ‘Auto’. This will give you control over the ‘Optimal RSI Lookback Length’ and ‘RSI Count’ within the Settings. Please note, it will likely take some “fine tuning” to find working settings without the Indicator timing out, but there are definitely times you can find better settings than our ‘Auto’ will create; especially on higher Time Frames. The Minimum our ‘Auto’ will create is:
Optimal RSI Lookback Length: 90
RSI Count: 20
The Maximum it will create is:
Optimal RSI Lookback Length: 200
RSI Count: 30
If there isn’t much bar index history, for instance, if you’re on the 1 Day and the pair is BTC/USDT you’ll get < 4000 Bar Indexes worth of data. For this reason it is possible to manually increase the settings to say:
Optimal RSI Lookback Length: 500
RSI Count: 50
But, please note, if you make it too high, it may also lead to inaccuracies.
We will conclude our Tutorial here, hopefully this has given you some insight as to how calculating our Optimal RSI and then using it within Machine Learning may create a more adaptive RSI.
Settings:
Optimal RSI:
Show Crossing Signals: Display signals where the RSI and RSI Cross.
Show Tables: Display Information Tables to show information like, Optimal RSI Length, Best Profit, New Optimal RSI Lookback Length and New RSI Count.
Show Bollinger Bands: Show RSI Bollinger Bands. These bands work like the TDI Indicator, except its length changes as it uses the current RSI Optimal Length.
Optimal RSI Type: This is how we calculate our Optimal RSI. Do we use all RSI and RSI MA Crossings or just when it crosses within the Extremities.
Adjust Optimal RSI Lookback and RSI Count: Auto means the script will automatically adjust the Optimal RSI Lookback Length and RSI Count based on the current Time Frame and Bar Index's on chart. This will attempt to stop the script from 'Taking too long to Execute'. Manual means you have full control of the Optimal RSI Lookback Length and RSI Count.
Optimal RSI Lookback Length: How far back are we looking to see which RSI length is optimal? Please note the more bars the lower this needs to be. For instance with BTC/USDT you can use 500 here on 1D but only 200 for 15 Minutes; otherwise it will timeout.
RSI Count: How many lengths are we checking? For instance, if our 'RSI Minimum Length' is 4 and this is 30, the valid RSI lengths we check is 4-34.
RSI Minimum Length: What is the RSI length we start our scans at? We are capped with RSI Count otherwise it will cause the Indicator to timeout, so we don't want to waste any processing power on irrelevant lengths.
RSI MA Length: What length are we using to calculate the optimal RSI cross' and likewise plot our RSI MA with?
Extremity Crossings RSI Backup Length: When there is no Optimal RSI (if using Extremity Crossings), which RSI should we use instead?
Machine Learning:
Use Rational Quadratics: Rationalizing our Close may be beneficial for usage within ML calculations.
Filter RSI and RSI MA: Should we filter the RSI's before usage in ML calculations? Essentially should we only use RSI data that are of the same type as our Optimal RSI? For instance if our Optimal RSI is Bullish (RSI > RSI MA), should we only use ML RSI's that are likewise bullish?
Machine Learning Type: Are we using a Simple ML Average, KNN Mean Average, KNN Exponential Average or None?
KNN Distance Type: We need to check if distance is within the KNN Min/Max distance, which distance checks are we using.
Machine Learning Length: How far back is our Machine Learning going to keep data for.
k-Nearest Neighbour (KNN) Length: How many k-Nearest Neighbours will we account for?
Fast ML Data Length: What is our Fast ML Length? This is used with our Slow Length to create our KNN Distance.
Slow ML Data Length: What is our Slow ML Length? This is used with our Fast Length to create our KNN Distance.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!

Machine Learning: Trend Lines [YinYangAlgorithms]Trend lines have always been a key indicator that may help predict many different types of price movements. They have been well known to create different types of formations such as: Pennants, Channels, Flags and Wedges. The type of formation they create is based on how the formation was created and the angle it was created. For instance, if there was a strong price increase and then there is a Wedge where both end points meet, this is considered a Bull Pennant. The formations Trend Lines create may be powerful tools that can help predict current Support and Resistance and also Future Momentum changes. However, not all Trend Lines will create formations, and alone they may stand as strong Support and Resistance locations on the Vertical.
The purpose of this Indicator is to apply Machine Learning logic to a Traditional Trend Line Calculation, and therefore allowing a new approach to a modern indicator of high usage. The results of such are quite interesting and goes to show the impacts a simple KNN Machine Learning model can have on Traditional Indicators.
Tutorial:
There are a few different settings within this Indicator. Many will greatly impact the results and if any are changed, lots will need ‘Fine Tuning’. So let's discuss the main toggles that have great effects and what they do before discussing the lengths. Currently in this example above we have the Indicator at its Default Settings. In this example, you can see how the Trend Lines act as key Support and Resistance locations. Due note, Support and Resistance are a relative term, as is their color. What starts off as Support or Resistance may change when the price crosses over / under them.
In the example above we have zoomed in and circled locations that exhibited markers of Support and Resistance along the Trend Lines. These Trend Lines are all created using the Default Settings. As you can see from the example above; just because it is a Green Upwards Trend Line, doesn’t mean it’s a Support Line. Support and Resistance is always shifting on Trend Lines based on the prices location relative to them.
We won’t go through all the Formations Trend Lines make, but the example above, we can see the Trend Lines formed a Downward Channel. Channels are when there are two parallel downwards Trend Lines that are at a relatively similar angle. This means that they won’t ever meet. What may happen when the price is within these channels, is it may bounce between the upper and lower bounds. These Channels may drive the price upwards or downwards, depending on if it is in an Upwards or Downwards Channel.
If you refer to the example above, you’ll notice that the Trend Lines are formed like traditional Trend Lines. They don’t stem from current Highs and Lows but rather Machine Learning Highs and Lows. More often than not, the Machine Learning approach to Trend Lines cause their start point and angle to be quite different than a Traditional Trend Line. Due to this, it may help predict Support and Resistance locations at are more uncommon and therefore can be quite useful.
In the example above we have turned off the toggle in Settings ‘Use Exponential Data Average’. This Settings uses a custom Exponential Data Average of the KNN rather than simply averaging the KNN. By Default it is enabled, but as you can see when it is disabled it may create some pretty strong lasting Trend Lines. This is why we advise you ZOOM OUT AS FAR AS YOU CAN. Trend Lines are only displayed when you’ve zoomed out far enough that their Start Point is visible.
As you can see in this example above, there were 3 major Upward Trend Lines created in 2020 that have had a major impact on Support and Resistance Locations within the last year. Lets zoom in and get a closer look.
We have zoomed in for this example above, and circled some of the major Support and Resistance locations that these Upward Trend Lines may have had a major impact on.
Please note, these Machine Learning Trend Lines aren’t a ‘One Size Fits All’ kind of thing. They are completely customizable within the Settings, so that you can get a tailored experience based on what Pair and Time Frame you are trading on.
When any values are changed within the Settings, you’ll likely need to ‘Fine Tune’ the rest of the settings until your desired result is met. By default the modifiable lengths within the Settings are:
Machine Learning Length: 50
KNN Length:5
Fast ML Data Length: 5
Slow ML Data Length: 30
For example, let's toggle ‘Use Exponential Data Averages’ back on and change ‘Fast ML Data Length’ from 5 to 20 and ‘Slow ML Data Length’ from 30 to 50.
As you can in the example above, all of the lines have changed. Although there are still some strong Support Locations created by the Upwards Trend Lines.
We will conclude our Tutorial here. Hopefully you’ve learned how to use Machine Learning Trend Lines and will be able to now see some more unorthodox Support and Resistance locations on the Vertical.
Settings:
Use Machine Learning Sources: If disabled Traditional Trend line sources (High and Low) will be used rather than Rational Quadratics.
Use KNN Distance Sorting: You can disable this if you wish to not have the Machine Learning Data sorted using KNN. If disabled trend line logic will be Traditional.
Use Exponential Data Average: This Settings uses a custom Exponential Data Average of the KNN rather than simply averaging the KNN.
Machine Learning Length: How strong is our Machine Learning Memory? Please note, when this value is too high the data is almost 'too' much and can lead to poor results.
K-Nearest Neighbour (KNN) Length: How many K-Nearest Neighbours are allowed with our Distance Clustering? Please note, too high or too low may lead to poor results.
Fast ML Data Length: Fast and Slow speed needs to be adjusted properly to see results. 3/5/7 all seem to work well for Fast.
Slow ML Data Length: Fast and Slow speed needs to be adjusted properly to see results. 20 - 50 all seem to work well for Slow.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!

Machine Learning: Support and Resistance [YinYangAlgorithms]Overview:
Support and Resistance is normally based upon Pivot Points and Highest Highs and Lowest Lows. Many times coders even incorporate Volume, RSI and other factors into the equation. However there may be a downside to doing a pure technical approach based on historical levels. We live in a time where Machine Learning is becoming more and more used; thus we have decided to create a Machine Learning Support and Resistance Projection based Indicator. Rather than using traditional Support and Resistance calculations using historical data, we have taken a rather different approach. This Indicator instead attempts to Predict and Project where Support and Resistance locations will be based on a Machine Learning Model using a form of KNN (k-Nearest Neighbors).
Since this indicator creates a Projection of where it deems Support and Resistance will be, it has the ability to move its Support and Resistance before the price even gets to it if it believes it will surpass its projections. This may create a more accurate placement of Support and Resistance as they’re not based on historical levels.
This Indicator does not Repaint.
How it works:
This Indicator makes its projections based on the source you provide (by default close) of the previous bar and submits the source, RSI and EMA to our Projection Function to get its projection of the current bar.
The Projection function essentially calculates potential movement after finding the differences between the source the MA from the current bar, previous bar and average over the span of Machine Learning Length.
Potential movement is defined as:
Average Difference + Average(Machine Learning Average, Average Last Distance)
Average Difference: (Absolute value of Current Source - Current MA) - (Absolute value of Machine Learning Average - Machine Learning MA)
Average Last Distance: Average(Current Source - Current MA, Previous Source - Previous MA)
It then predicts the next bars directional movement (bullish or bearish bar) using several factors:
Previous Source > Previous MA
Current Source - Current MA > Average Source - Average MA
Current RSI > Previous RSI
Current RSI > 30 and Previous RSI <= 30
Current RSI < 70 and Previous RSI >= 70
This helps us to predict the direction the next bar may move.
We then calculate a multiplier that we apply to our Potential Movement value to get our final result which is our Current Bars Close Projection.
Our multiplier is calculated using:
(Current RSI > 30 and Previous RSI <= 30) OR (Current RSI < 70 and Previous RSI >= 70)
Current Source - Current MA > Previous Source - Previous MA
We then create an array and fill it with the previous X projections (Machine Learning Length) and send it to another function. This function, if told to, will sort the data accordingly and then output the KNN average of the length given.
We calculate and plot various KNN lengths to create different Zones:
Strong Support: Length of 2 but sort the data Ascending (low to high)
Strong Resistance: Length of 2 but sort the data Descending (high to low)
Support: Length of Machine Length Length / 10 or Min of 2 sorted by Ascending
Resistance: Length of Machine Length Length / 10 or Min of 2 sorted by Descending
There are also 4 other plots you may be wondering what they are, there is your AVG, VWMA, Long Term Memory and Current Projection.
By default your Current Projection is disabled in settings but you can enable it if you are curious to see how the projections for each close are calculated. It is, however, not a crucial point of interest (white line).
The average is simply the average value of the Machine Learning Data (purple line).
The VWMA is a VWMA calculation applied to our Data over a length specified in settings (by default 1)(blue line). The VWMA is crucial when combined with the Avg as they can cross over and under each other. These crosses represent potential Bullish and Bearish zones.
Lastly, but certainly not least, we have the Long Term Memory (maroon line). The Long Term Memory can be displayed either as an ‘Average’, ‘Hard Line’ or ‘None’. The Long Term Average is only updated every Machine Learning Length Bar Index’s and is populated with the average of the Machine Learning Data. For Instance, if Machine Learning Length is set to 100, the Long Term Memory is only updated every 100 bars, and since its length is the same as the Machine Learning Length, that means its data is composed of 10,000 bars worth of data. The Long Term Memory may be very beneficial for determining where Support and Resistance lie over the Long Term within a Machine Learning Algorithm. When set to ‘Average’ it plots the connection lines diagonally, and although they may be more visually appealing, they’re less useful when it comes to actually seeing support and resistance as generally speaking, support and resistance lie on the horizontal. When set to ‘Hard Line’ the Long Term Memory is connected with hard lines and holds the price value until the next time it is updated. This makes it much more useful for potentially identifying Support and Resistance.
Tutorial:
Here is an overview of what the Indicator looks like, now let's start to dissect it.
In the example above we can see how all of the lines between the Major Support and Resistance zones may act as BOTH Support and Resistance depending on which side the price is currently on. In the circle on the left, we can see how it can fluctuate between the two. If you look at the circle on the right, we can see how the Average line acts as a strong support before it fails to maintain it. Generally speaking, most Support and Resistance locations may potentially fail to hold after 3 tests, as the Average did in this example.
As you can see, the Support and Resistance doesn’t wait to be tested before adjusting, which is why there are 2 lines which create their zones. The inner line is the Support/Resistance and the outer line is the Strong Support/Resistance. The Yellow Circle shows the inner line was able to calculate the moving resistance correctly and then adjusted accordingly as it was projecting the price to keep increasing. However, if you look at the White Circle, you can see that since there was first a crash, and then parabolic movement, that the inner zone could not move and predict the resistance as well as the outer zone could.
We consider the price to be ‘Overvalued’ when it is above the VWMA (blue line) and ‘Undervalued’ when it is below the VWMA. It is considered ‘fair’ price when it is within the VWMA to Average zone (between the blue and purple lines). If you look at the example above, you’ll notice where the two yellow circles are, it is not only considered ‘Overvalued’, but it then proceeds to ride the inner resistance line upwards. This is common when the market is overly bullish and vice versa when it is bearish. Please keep in mind, although it is common, it doesn’t mean a correction can’t happen.
In this example above we look at the last bull run that may have started due to the halving. This bull run was very bullish as you can see in the example above. The price was constantly sitting within the Resistance Zone and the VWMA that was very close to it was constantly acting as a Support. Naturally, due to the Algorithm used in this Indicator, as the momentum starts to slow down, the VWMA (blue line) will start to space out more and more from the Resistance Zone. This doesn’t mean the momentum is gone, it just means it may be slowing down.
Unfortunately we have to study the Bear Market with a different perspective than the Bull Market. However, there are still some similarities within the two. If you refer to the example above and the previous example, you can clearly see that the Bull Market loves to stay with the Resistance Zone and use the VWMA as a Support. However, the Bear Market does not. This is a normal occurrence, however we can see from the example above you may see a correction / horizontal movement when the Outer Support Line is touched. If you look at all 3 yellow circles, the Outer Support Line was touched, then either a small correction or horizontal consolidation occurred.
We will conclude our Tutorial here, hopefully you’ll be able to benefit from a moving Support and Resistance calculated with Machine Learning that projects its locations, rather than using traditional calculations.
Settings:
Source: This source is the base for all our calculations
Machine Learning Length: How much projection data are we storing and using to make calculations.
Smoothing Length: We need to smooth calculations such as RSI, EMA and VWMA. What length are we smoothing it with?
VWMA ML Projection Length: How far into our Machine Learning data should we average for our VWMA. Please note the 'Smoothing Length' is still applied here after getting the Projection Average.
Long Term Memory: Long term memory has the same storage length but is only updated once per Machine Learning Length. For instance, if Machine Learning Length is 100, it will save the Average of our data once every 100 bars. This means its memory is an average of 10,000 bars of Machine Learning. 'Average' connects its values diagonally whereas 'Hard Line' holds its value until it changes.
Use Average Last Distance In Potential Movement: This can help accuracy but generally also displaces the Support and Resistance by projecting it further.
Show Current Projection: Projections occur for each bar, and our Machine Learning utilizes these projections by storing and evaluating them. This toggle will display the Current Projection Line which is used to create all our Projections.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!

AI Momentum [YinYang]Overview:
AI Momentum is a kernel function based momentum Indicator. It uses Rational Quadratics to help smooth out the Moving Averages, this may give them a more accurate result. This Indicator has 2 main uses, first it displays ‘Zones’ that help you visualize the potential movement areas and when the price is out of bounds (Overvalued or Undervalued). Secondly it creates signals that display the momentum of the current trend.
The Zones are composed of the Highest Highs and Lowest lows turned into a Rational Quadratic over varying lengths. These create our Rational High and Low zones. There is however a second zone. The second zone is composed of the avg of the Inner High and Inner Low zones (yellow line) and the Rational Quadratic of the current Close. This helps to create a second zone that is within the High and Low bounds that may represent momentum changes within these zones. When the Rationalized Close crosses above the High and Low Zone Average it may signify a bullish momentum change and vice versa when it crosses below.
There are 3 different signals created to display momentum:
Bullish and Bearish Momentum. These signals display when there is current bullish or bearish momentum happening within the trend. When the momentum changes there will likely be a lull where there are neither Bullish or Bearish momentum signals. These signals may be useful to help visualize when the momentum has started and stopped for both the bulls and the bears. Bullish Momentum is calculated by checking if the Rational Quadratic Close > Rational Quadratic of the Highest OHLC4 smoothed over a VWMA. The Bearish Momentum is calculated by checking the opposite.
Overly Bullish and Bearish Momentum. These signals occur when the bar has Bullish or Bearish Momentum and also has an Rationalized RSI greater or less than a certain level. Bullish is >= 57 and Bearish is <= 43. There is also the option to ‘Factor Volume’ into these signals. This means, the Overly Bullish and Bearish Signals will only occur when the Rationalized Volume > VWMA Rationalized Volume as well as the previously mentioned factors above. This can be useful for removing ‘clutter’ as volume may dictate when these momentum changes will occur, but it can also remove some of the useful signals and you may miss the swing too if the volume just was low. Overly Bullish and Bearish Momentum may dictate when a momentum change will occur. Remember, they are OVERLY Bullish and Bearish, meaning there is a chance a correction may occur around these signals.
Bull and Bear Crosses. These signals occur when the Rationalized Close crosses the Gaussian Close that is 2 bars back. These signals may show when there is a strong change in momentum, but be careful as more often than not they’re predicting that the momentum may change in the opposite direction.
Tutorial:
As we can see in the example above, generally what happens is we get the regular Bullish or Bearish momentum, followed by the Rationalized Close crossing the Zone average and finally the Overly Bullish or Bearish signals. This is normally the order of operations but isn’t always how it happens as sometimes momentum changes don’t make it that far; also the Rationalized Close and Zone Average don’t follow any of the same math as the Signals which can result in differing appearances. The Bull and Bear Crosses are also quite sporadic in appearance and don’t generally follow any sort of order of operations. However, they may occur as a Predictor between Bullish and Bearish momentum, signifying the beginning of the momentum change.
The Bull and Bear crosses may be a Predictor of momentum change. They generally happen when there is no Bullish or Bearish momentum happening; and this helps to add strength to their prediction. When they occur during momentum (orange circle) there is a less likely chance that it will happen, and may instead signify the exact opposite; it may help predict a large spike in momentum in the direction of the Bullish or Bearish momentum. In the case of the orange circle, there is currently Bearish Momentum and therefore the Bull Cross may help predict a large momentum movement is about to occur in favor of the Bears.
We have disabled signals here to properly display and talk about the zones. As you can see, Rationalizing the Highest Highs and Lowest Lows over 2 different lengths creates inner and outer bounds that help to predict where parabolic movement and momentum may move to. Our Inner and Outer zones are great for seeing potential Support and Resistance locations.
The secondary zone, which can cross over and change from Green to Red is also a very important zone. Let's zoom in and talk about it specifically.
The Middle Zone Crosses may help deduce where parabolic movement and strong momentum changes may occur. Generally what may happen is when the cross occurs, you will see parabolic movement to the High / Low zones. This may be the Inner zone but can sometimes be the outer zone too. The hard part is sometimes it can be a Fakeout, like displayed with the Blue Circle. The Cross doesn’t mean it may move to the opposing side, sometimes it may just be predicting Parabolic movement in a general sense.
When we turn the Momentum Signals back on, we can see where the Fakeout occurred that it not only almost hit the Inner Low Zone but it also exhibited 2 Overly Bearish Signals. Remember, Overly bearish signals mean a momentum change in favor of the Bulls may occur soon and overly Bullish signals mean a momentum change in favor of the Bears may occur soon.
You may be wondering, well what does “may occur soon” mean and how do we tell?
The purpose of the momentum signals is not only to let you know when Momentum has occurred and when it is still prevalent. It also matters A LOT when it has STOPPED!
In this example above, we look at when the Overly Bullish and Bearish Momentum has STOPPED. As you can see, when the Overly Bullish or Bearish Momentum stopped may be a strong predictor of potential momentum change in the opposing direction.
We will conclude our Tutorial here, hopefully this Indicator has been helpful for showing you where momentum is occurring and help predict how far it may move. We have been dabbling with and are planning on releasing a Strategy based on this Indicator shortly.
Settings:
1. Momentum:
Show Signals: Sometimes it can be difficult to visualize the zones with signals enabled.
Factor Volume: Factor Volume only applies to Overly Bullish and Bearish Signals. It's when the Volume is > VWMA Volume over the Smoothing Length.
Zone Inside Length: The Zone Inside is the Inner zone of the High and Low. This is the length used to create it.
Zone Outside Length: The Zone Outside is the Outer zone of the High and Low. This is the length used to create it.
Smoothing length: Smoothing length is the length used to smooth out our Bullish and Bearish signals, along with our Overly Bullish and Overly Bearish Signals.
2. Kernel Settings:
Lookback Window: The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars. Recommended range: 3-50.
Relative Weighting: Relative weighting of time frames. As this value approaches zero, the longer time frames will exert more influence on the estimation. As this value approaches infinity, the behavior of the Rational Quadratic Kernel will become identical to the Gaussian kernel. Recommended range: 0.25-25.
Start Regression at Bar: Bar index on which to start regression. The first bars of a chart are often highly volatile, and omission of these initial bars often leads to a better overall fit. Recommended range: 5-25.
If you have any questions, comments, ideas or concerns please don't hesitate to contact us.
HAPPY TRADING!

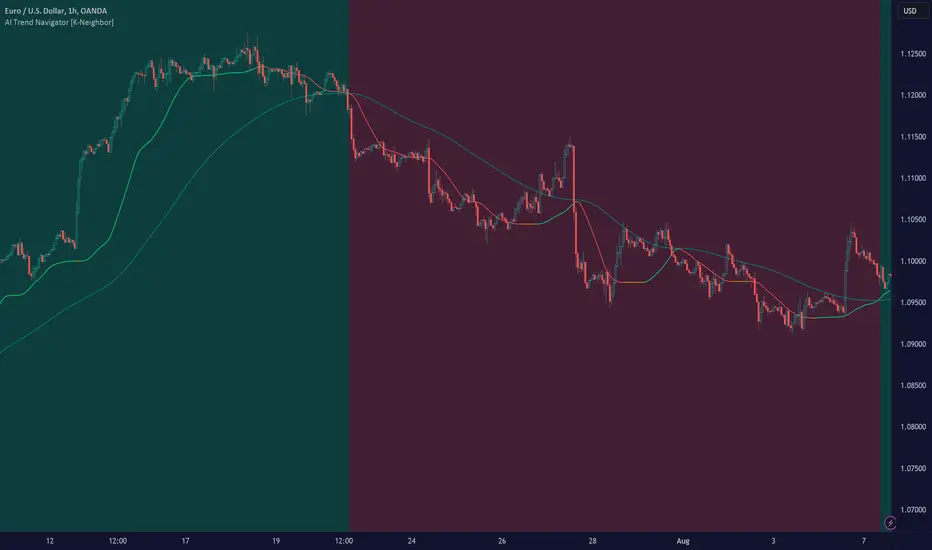
AI Trend Navigator [K-Neighbor]█ Overview
In the evolving landscape of trading and investment, the demand for sophisticated and reliable tools is ever-growing. The AI Trend Navigator is an indicator designed to meet this demand, providing valuable insights into market trends and potential future price movements. The AI Trend Navigator indicator is designed to predict market trends using the k-Nearest Neighbors (KNN) classifier.
By intelligently analyzing recent price actions and emphasizing similar values, it helps traders to navigate complex market conditions with confidence. It provides an advanced way to analyze trends, offering potentially more accurate predictions compared to simpler trend-following methods.
█ Calculations
KNN Moving Average Calculation: The core of the algorithm is a KNN Moving Average that computes the mean of the 'k' closest values to a target within a specified window size. It does this by iterating through the window, calculating the absolute differences between the target and each value, and then finding the mean of the closest values. The target and value are selected based on user preferences (e.g., using the VWAP or Volatility as a target).
KNN Classifier Function: This function applies the k-nearest neighbor algorithm to classify the price action into positive, negative, or neutral trends. It looks at the nearest 'k' bars, calculates the Euclidean distance between them, and categorizes them based on the relative movement. It then returns the prediction based on the highest count of positive, negative, or neutral categories.
█ How to use
Traders can use this indicator to identify potential trend directions in different markets.
Spotting Trends: Traders can use the KNN Moving Average to identify the underlying trend of an asset. By focusing on the k closest values, this component of the indicator offers a clearer view of the trend direction, filtering out market noise.
Trend Confirmation: The KNN Classifier component can confirm existing trends by predicting the future price direction. By aligning predictions with current trends, traders can gain more confidence in their trading decisions.
█ Settings
PriceValue: This determines the type of price input used for distance calculation in the KNN algorithm.
hl2: Uses the average of the high and low prices.
VWAP: Uses the Volume Weighted Average Price.
VWAP: Uses the Volume Weighted Average Price.
Effect: Changing this input will modify the reference values used in the KNN classification, potentially altering the predictions.
TargetValue: This sets the target variable that the KNN classification will attempt to predict.
Price Action: Uses the moving average of the closing price.
VWAP: Uses the Volume Weighted Average Price.
Volatility: Uses the Average True Range (ATR).
Effect: Selecting different targets will affect what the KNN is trying to predict, altering the nature and intent of the predictions.
Number of Closest Values: Defines how many closest values will be considered when calculating the mean for the KNN Moving Average.
Effect: Increasing this value makes the algorithm consider more nearest neighbors, smoothing the indicator and potentially making it less reactive. Decreasing this value may make the indicator more sensitive but possibly more prone to noise.
Neighbors: This sets the number of neighbors that will be considered for the KNN Classifier part of the algorithm.
Effect: Adjusting the number of neighbors affects the sensitivity and smoothness of the KNN classifier.
Smoothing Period: Defines the smoothing period for the moving average used in the KNN classifier.
Effect: Increasing this value would make the KNN Moving Average smoother, potentially reducing noise. Decreasing it would make the indicator more reactive but possibly more prone to false signals.
█ What is K-Nearest Neighbors (K-NN) algorithm?
At its core, the K-NN algorithm recognizes patterns within market data and analyzes the relationships and similarities between data points. By considering the 'K' most similar instances (or neighbors) within a dataset, it predicts future price movements based on historical trends. The K-Nearest Neighbors (K-NN) algorithm is a type of instance-based or non-generalizing learning. While K-NN is considered a relatively simple machine-learning technique, it falls under the AI umbrella.
We can classify the K-Nearest Neighbors (K-NN) algorithm as a form of artificial intelligence (AI), and here's why:
Machine Learning Component: K-NN is a type of machine learning algorithm, and machine learning is a subset of AI. Machine learning is about building algorithms that allow computers to learn from and make predictions or decisions based on data. Since K-NN falls under this category, it is aligned with the principles of AI.
Instance-Based Learning: K-NN is an instance-based learning algorithm. This means that it makes decisions based on the entire training dataset rather than deriving a discriminative function from the dataset. It looks at the 'K' most similar instances (neighbors) when making a prediction, hence adapting to new information if the dataset changes. This adaptability is a hallmark of intelligent systems.
Pattern Recognition: The core of K-NN's functionality is recognizing patterns within data. It identifies relationships and similarities between data points, something akin to human pattern recognition, a key aspect of intelligence.
Classification and Regression: K-NN can be used for both classification and regression tasks, two fundamental problems in machine learning and AI. The indicator code is used for trend classification, a predictive task that aligns with the goals of AI.
Simplicity Doesn't Exclude AI: While K-NN is often considered a simpler algorithm compared to deep learning models, simplicity does not exclude something from being AI. Many AI systems are built on simple rules and can be combined or scaled to create complex behavior.
No Explicit Model Building: Unlike traditional statistical methods, K-NN does not build an explicit model during training. Instead, it waits until a prediction is required and then looks at the 'K' nearest neighbors from the training data to make that prediction. This lazy learning approach is another aspect of machine learning, part of the broader AI field.
-----------------
Disclaimer
The information contained in my Scripts/Indicators/Ideas/Algos/Systems does not constitute financial advice or a solicitation to buy or sell any securities of any type. I will not accept liability for any loss or damage, including without limitation any loss of profit, which may arise directly or indirectly from the use of or reliance on such information.
All investments involve risk, and the past performance of a security, industry, sector, market, financial product, trading strategy, backtest, or individual's trading does not guarantee future results or returns. Investors are fully responsible for any investment decisions they make. Such decisions should be based solely on an evaluation of their financial circumstances, investment objectives, risk tolerance, and liquidity needs.
My Scripts/Indicators/Ideas/Algos/Systems are only for educational purposes!
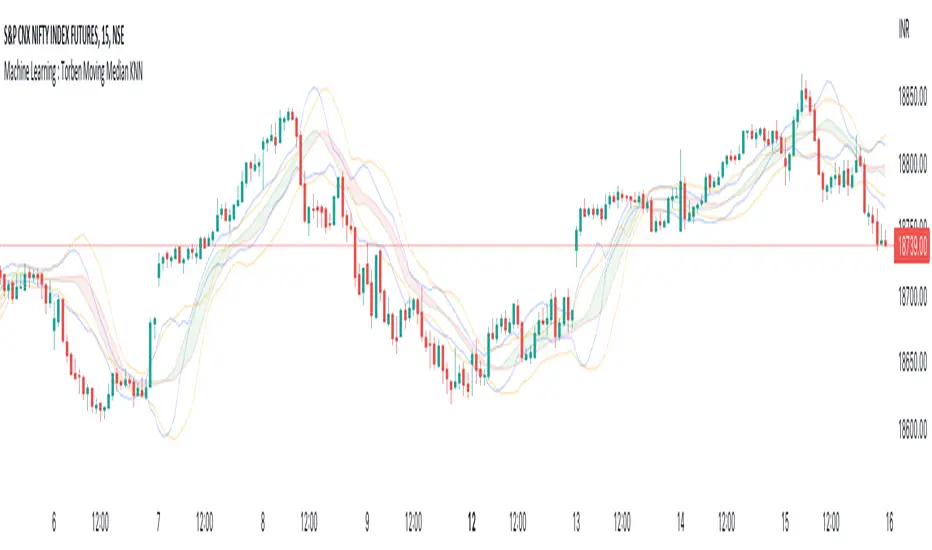
Machine Learning : Torben's Moving Median KNN BandsWhat is Median Filtering ?
Median filtering is a non-linear digital filtering technique, often used to remove noise from an image or signal. Such noise reduction is a typical pre-processing step to improve the results of later processing (for example, edge detection on an image). Median filtering is very widely used in digital image processing because, under certain conditions, it preserves edges while removing noise (but see the discussion below), also having applications in signal processing.
The main idea of the median filter is to run through the signal entry by entry, replacing each entry with the median of neighboring entries. The pattern of neighbors is called the "window", which slides, entry by entry, over the entire signal. For one-dimensional signals, the most obvious window is just the first few preceding and following entries, whereas for two-dimensional (or higher-dimensional) data the window must include all entries within a given radius or ellipsoidal region (i.e. the median filter is not a separable filter).
The median filter works by taking the median of all the pixels in a neighborhood around the current pixel. The median is the middle value in a sorted list of numbers. This means that the median filter is not sensitive to the order of the pixels in the neighborhood, and it is not affected by outliers (very high or very low values).
The median filter is a very effective way to remove noise from images. It can remove both salt and pepper noise (random white and black pixels) and Gaussian noise (randomly distributed pixels with a Gaussian distribution). The median filter is also very good at preserving edges, which is why it is often used as a pre-processing step for edge detection.
However, the median filter can also blur images. This is because the median filter replaces each pixel with the value of the median of its neighbors. This can cause the edges of objects in the image to be smoothed out. The amount of blurring depends on the size of the window used by the median filter. A larger window will blur more than a smaller window.
The median filter is a very versatile tool that can be used for a variety of tasks in image processing. It is a good choice for removing noise and preserving edges, but it can also blur images. The best way to use the median filter is to experiment with different window sizes to find the setting that produces the desired results.
What is this Indicator ?
K-nearest neighbors (KNN) is a simple, non-parametric machine learning algorithm that can be used for both classification and regression tasks. The basic idea behind KNN is to find the K most similar data points to a new data point and then use the labels of those K data points to predict the label of the new data point.
Torben's moving median is a variation of the median filter that is used to remove noise from images. The median filter works by replacing each pixel in an image with the median of its neighbors. Torben's moving median works in a similar way, but it also averages the values of the neighbors. This helps to reduce the amount of blurring that can occur with the median filter.
KNN over Torben's moving median is a hybrid algorithm that combines the strengths of both KNN and Torben's moving median. KNN is able to learn the underlying distribution of the data, while Torben's moving median is able to remove noise from the data. This combination can lead to better performance than either algorithm on its own.
To implement KNN over Torben's moving median, we first need to choose a value for K. The value of K controls how many neighbors are used to predict the label of a new data point. A larger value of K will make the algorithm more robust to noise, but it will also make the algorithm less sensitive to local variations in the data.
Once we have chosen a value for K, we need to train the algorithm on a dataset of labeled data points. The training dataset will be used to learn the underlying distribution of the data.
Once the algorithm is trained, we can use it to predict the labels of new data points. To do this, we first need to find the K most similar data points to the new data point. We can then use the labels of those K data points to predict the label of the new data point.
KNN over Torben's moving median is a simple, yet powerful algorithm that can be used for a variety of tasks. It is particularly well-suited for tasks where the data is noisy or where the underlying distribution of the data is unknown.
Here are some of the advantages of using KNN over Torben's moving median:
KNN is able to learn the underlying distribution of the data.
KNN is robust to noise.
KNN is not sensitive to local variations in the data.
Here are some of the disadvantages of using KNN over Torben's moving median:
KNN can be computationally expensive for large datasets.
KNN can be sensitive to the choice of K.
KNN can be slow to train.
Machine Learning: Lorentzian Classification█ OVERVIEW
A Lorentzian Distance Classifier (LDC) is a Machine Learning classification algorithm capable of categorizing historical data from a multi-dimensional feature space. This indicator demonstrates how Lorentzian Classification can also be used to predict the direction of future price movements when used as the distance metric for a novel implementation of an Approximate Nearest Neighbors (ANN) algorithm.
█ BACKGROUND
In physics, Lorentzian space is perhaps best known for its role in describing the curvature of space-time in Einstein's theory of General Relativity (2). Interestingly, however, this abstract concept from theoretical physics also has tangible real-world applications in trading.
Recently, it was hypothesized that Lorentzian space was also well-suited for analyzing time-series data (4), (5). This hypothesis has been supported by several empirical studies that demonstrate that Lorentzian distance is more robust to outliers and noise than the more commonly used Euclidean distance (1), (3), (6). Furthermore, Lorentzian distance was also shown to outperform dozens of other highly regarded distance metrics, including Manhattan distance, Bhattacharyya similarity, and Cosine similarity (1), (3). Outside of Dynamic Time Warping based approaches, which are unfortunately too computationally intensive for PineScript at this time, the Lorentzian Distance metric consistently scores the highest mean accuracy over a wide variety of time series data sets (1).
Euclidean distance is commonly used as the default distance metric for NN-based search algorithms, but it may not always be the best choice when dealing with financial market data. This is because financial market data can be significantly impacted by proximity to major world events such as FOMC Meetings and Black Swan events. This event-based distortion of market data can be framed as similar to the gravitational warping caused by a massive object on the space-time continuum. For financial markets, the analogous continuum that experiences warping can be referred to as "price-time".
Below is a side-by-side comparison of how neighborhoods of similar historical points appear in three-dimensional Euclidean Space and Lorentzian Space:
This figure demonstrates how Lorentzian space can better accommodate the warping of price-time since the Lorentzian distance function compresses the Euclidean neighborhood in such a way that the new neighborhood distribution in Lorentzian space tends to cluster around each of the major feature axes in addition to the origin itself. This means that, even though some nearest neighbors will be the same regardless of the distance metric used, Lorentzian space will also allow for the consideration of historical points that would otherwise never be considered with a Euclidean distance metric.
Intuitively, the advantage inherent in the Lorentzian distance metric makes sense. For example, it is logical that the price action that occurs in the hours after Chairman Powell finishes delivering a speech would resemble at least some of the previous times when he finished delivering a speech. This may be true regardless of other factors, such as whether or not the market was overbought or oversold at the time or if the macro conditions were more bullish or bearish overall. These historical reference points are extremely valuable for predictive models, yet the Euclidean distance metric would miss these neighbors entirely, often in favor of irrelevant data points from the day before the event. By using Lorentzian distance as a metric, the ML model is instead able to consider the warping of price-time caused by the event and, ultimately, transcend the temporal bias imposed on it by the time series.
For more information on the implementation details of the Approximate Nearest Neighbors (ANN) algorithm used in this indicator, please refer to the detailed comments in the source code.
█ HOW TO USE
Below is an explanatory breakdown of the different parts of this indicator as it appears in the interface:
Below is an explanation of the different settings for this indicator:
General Settings:
Source - This has a default value of "hlc3" and is used to control the input data source.
Neighbors Count - This has a default value of 8, a minimum value of 1, a maximum value of 100, and a step of 1. It is used to control the number of neighbors to consider.
Max Bars Back - This has a default value of 2000.
Feature Count - This has a default value of 5, a minimum value of 2, and a maximum value of 5. It controls the number of features to use for ML predictions.
Color Compression - This has a default value of 1, a minimum value of 1, and a maximum value of 10. It is used to control the compression factor for adjusting the intensity of the color scale.
Show Exits - This has a default value of false. It controls whether to show the exit threshold on the chart.
Use Dynamic Exits - This has a default value of false. It is used to control whether to attempt to let profits ride by dynamically adjusting the exit threshold based on kernel regression.
Feature Engineering Settings:
Note: The Feature Engineering section is for fine-tuning the features used for ML predictions. The default values are optimized for the 4H to 12H timeframes for most charts, but they should also work reasonably well for other timeframes. By default, the model can support features that accept two parameters (Parameter A and Parameter B, respectively). Even though there are only 4 features provided by default, the same feature with different settings counts as two separate features. If the feature only accepts one parameter, then the second parameter will default to EMA-based smoothing with a default value of 1. These features represent the most effective combination I have encountered in my testing, but additional features may be added as additional options in the future.
Feature 1 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Feature 2 - This has a default value of "WT" and options are: "RSI", "WT", "CCI", "ADX".
Feature 3 - This has a default value of "CCI" and options are: "RSI", "WT", "CCI", "ADX".
Feature 4 - This has a default value of "ADX" and options are: "RSI", "WT", "CCI", "ADX".
Feature 5 - This has a default value of "RSI" and options are: "RSI", "WT", "CCI", "ADX".
Filters Settings:
Use Volatility Filter - This has a default value of true. It is used to control whether to use the volatility filter.
Use Regime Filter - This has a default value of true. It is used to control whether to use the trend detection filter.
Use ADX Filter - This has a default value of false. It is used to control whether to use the ADX filter.
Regime Threshold - This has a default value of -0.1, a minimum value of -10, a maximum value of 10, and a step of 0.1. It is used to control the Regime Detection filter for detecting Trending/Ranging markets.
ADX Threshold - This has a default value of 20, a minimum value of 0, a maximum value of 100, and a step of 1. It is used to control the threshold for detecting Trending/Ranging markets.
Kernel Regression Settings:
Trade with Kernel - This has a default value of true. It is used to control whether to trade with the kernel.
Show Kernel Estimate - This has a default value of true. It is used to control whether to show the kernel estimate.
Lookback Window - This has a default value of 8 and a minimum value of 3. It is used to control the number of bars used for the estimation. Recommended range: 3-50
Relative Weighting - This has a default value of 8 and a step size of 0.25. It is used to control the relative weighting of time frames. Recommended range: 0.25-25
Start Regression at Bar - This has a default value of 25. It is used to control the bar index on which to start regression. Recommended range: 0-25
Display Settings:
Show Bar Colors - This has a default value of true. It is used to control whether to show the bar colors.
Show Bar Prediction Values - This has a default value of true. It controls whether to show the ML model's evaluation of each bar as an integer.
Use ATR Offset - This has a default value of false. It controls whether to use the ATR offset instead of the bar prediction offset.
Bar Prediction Offset - This has a default value of 0 and a minimum value of 0. It is used to control the offset of the bar predictions as a percentage from the bar high or close.
Backtesting Settings:
Show Backtest Results - This has a default value of true. It is used to control whether to display the win rate of the given configuration.
█ WORKS CITED
(1) R. Giusti and G. E. A. P. A. Batista, "An Empirical Comparison of Dissimilarity Measures for Time Series Classification," 2013 Brazilian Conference on Intelligent Systems, Oct. 2013, DOI: 10.1109/bracis.2013.22.
(2) Y. Kerimbekov, H. Ş. Bilge, and H. H. Uğurlu, "The use of Lorentzian distance metric in classification problems," Pattern Recognition Letters, vol. 84, 170–176, Dec. 2016, DOI: 10.1016/j.patrec.2016.09.006.
(3) A. Bagnall, A. Bostrom, J. Large, and J. Lines, "The Great Time Series Classification Bake Off: An Experimental Evaluation of Recently Proposed Algorithms." ResearchGate, Feb. 04, 2016.
(4) H. Ş. Bilge, Yerzhan Kerimbekov, and Hasan Hüseyin Uğurlu, "A new classification method by using Lorentzian distance metric," ResearchGate, Sep. 02, 2015.
(5) Y. Kerimbekov and H. Şakir Bilge, "Lorentzian Distance Classifier for Multiple Features," Proceedings of the 6th International Conference on Pattern Recognition Applications and Methods, 2017, DOI: 10.5220/0006197004930501.
(6) V. Surya Prasath et al., "Effects of Distance Measure Choice on KNN Classifier Performance - A Review." .
█ ACKNOWLEDGEMENTS
@veryfid - For many invaluable insights, discussions, and advice that helped to shape this project.
@capissimo - For open sourcing his interesting ideas regarding various KNN implementations in PineScript, several of which helped inspire my original undertaking of this project.
@RikkiTavi - For many invaluable physics-related conversations and for his helping me develop a mechanism for visualizing various distance algorithms in 3D using JavaScript
@jlaurel - For invaluable literature recommendations that helped me to understand the underlying subject matter of this project.
@annutara - For help in beta-testing this indicator and for sharing many helpful ideas and insights early on in its development.
@jasontaylor7 - For helping to beta-test this indicator and for many helpful conversations that helped to shape my backtesting workflow
@meddymarkusvanhala - For helping to beta-test this indicator
@dlbnext - For incredibly detailed backtesting testing of this indicator and for sharing numerous ideas on how the user experience could be improved.

Machine Learning: kNN (New Approach)Description:
kNN is a very robust and simple method for data classification and prediction. It is very effective if the training data is large. However, it is distinguished by difficulty at determining its main parameter, K (a number of nearest neighbors), beforehand. The computation cost is also quite high because we need to compute distance of each instance to all training samples. Nevertheless, in algorithmic trading KNN is reported to perform on a par with such techniques as SVM and Random Forest. It is also widely used in the area of data science.
The input data is just a long series of prices over time without any particular features. The value to be predicted is just the next bar's price. The way that this problem is solved for both nearest neighbor techniques and for some other types of prediction algorithms is to create training records by taking, for instance, 10 consecutive prices and using the first 9 as predictor values and the 10th as the prediction value. Doing this way, given 100 data points in your time series you could create 10 different training records. It's possible to create even more training records than 10 by creating a new record starting at every data point. For instance, you could take the first 10 data points and create a record. Then you could take the 10 consecutive data points starting at the second data point, the 10 consecutive data points starting at the third data point, etc.
By default, shown are only 10 initial data points as predictor values and the 6th as the prediction value.
Here is a step-by-step workthrough on how to compute K nearest neighbors (KNN) algorithm for quantitative data:
1. Determine parameter K = number of nearest neighbors.
2. Calculate the distance between the instance and all the training samples. As we are dealing with one-dimensional distance, we simply take absolute value from the instance to value of x (| x – v |).
3. Rank the distance and determine nearest neighbors based on the K'th minimum distance.
4. Gather the values of the nearest neighbors.
5. Use average of nearest neighbors as the prediction value of the instance.
The original logic of the algorithm was slightly modified, and as a result at approx. N=17 the resulting curve nicely approximates that of the sma(20). See the description below. Beside the sma-like MA this algorithm also gives you a hint on the direction of the next bar move.
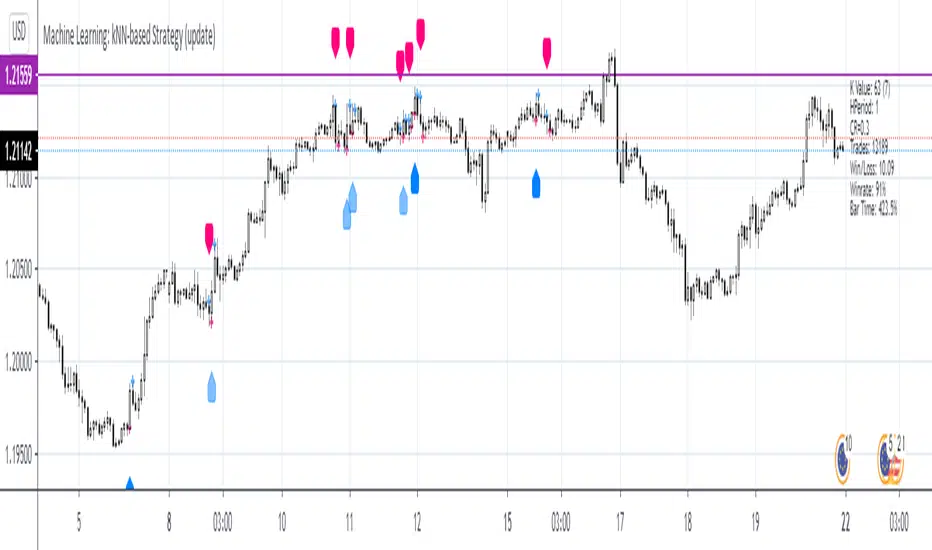
Machine Learning: kNN-based Strategy (update)kNN-based Strategy (FX and Crypto)
Description:
This update to the popular kNN-based strategy features:
improvements in the business logic,
an adjustible k value for the kNN model,
one more feature (MOM),
a streamlined signal filter and
some other minor fixes.
Now this script works in all timeframes !
I intentionally decided to publish this script separately
in order for the users to see the differences.
Machine Learning: kNN-based Strategy (mtf)This is a multi-timeframe version of the kNN-based strategy.

Machine Learning: kNN-based StrategykNN-based Strategy (FX and Crypto)
Description:
This strategy uses a classic machine learning algorithm - k Nearest Neighbours (kNN) - to let you find a prediction for the next (tomorrow's, next month's, etc.) market move. Being an unsupervised machine learning algorithm, kNN is one of the most simple learning algorithms.
To do a prediction of the next market move, the kNN algorithm uses the historic data, collected in 3 arrays - feature1, feature2 and directions, - and finds the k-nearest
neighbours of the current indicator(s) values.
The two dimensional kNN algorithm just has a look on what has happened in the past when the two indicators had a similar level. It then looks at the k nearest neighbours,
sees their state and thus classifies the current point.
The kNN algorithm offers a framework to test all kinds of indicators easily to see if they have got any *predictive value*. One can easily add cog, wpr and others.
Note: TradingViews's playback feature helps to see this strategy in action.
Warning: Signals ARE repainting.
Style tags: Trend Following, Trend Analysis
Asset class: Equities, Futures, ETFs, Currencies and Commodities
Dataset: FX Minutes/Hours+++/Days
