TUF_LOGICThe TUF_LOGIC library incorporates three-valued logic (also known as trilean logic) into Pine Script, enabling the representation of states beyond the binary True and False to include an 'Uncertain' state. This addition is particularly apt for financial market contexts where information may not always be black or white, accommodating scenarios of partial or ambiguous data.
Key Features:
Trilean Data Type: Defines a tri type, facilitating the representation of True (1), Uncertain (0), and False (-1) states, thus accommodating a more nuanced approach to logical evaluation.
Validation and Conversion: Includes methods like validate, to ensure trilean variables conform to expected states, and to_bool, for converting trilean to boolean values, enhancing interoperability with binary logic systems.
Core Logical Operations: Extends traditional logical operators (AND, OR, NOT, XOR, EQUALITY) to work within the trilean domain, enabling complex conditionals that reflect real-world uncertainties.
Specialized Logical Operations:
Implication Operators: Features IMP_K (Kleene's), IMP_L (Łukasiewicz's), and IMP_RM3, offering varied approaches to logical implication within the trilean framework.
Possibility, Necessity, and Contingency Operators: Implements MA ("it is possible that..."), LA ("it is necessary that..."), and IA ("it is unknown/contingent that..."), derived from Tarski-Łukasiewicz's modal logic attempts, enriching the library with modal logic capabilities.
Unanimity Functions: The UNANIMOUS operator assesses complete agreement among trilean values, useful for scenarios requiring consensus or uniformity across multiple indicators or conditions.
This library is developed to support scenarios in financial trading and analysis where decisions might hinge on more than binary outcomes. By incorporating modal logic aspects and providing a framework for handling uncertainty through the MA, LA, and IA operations, TUF_LOGIC bridges the gap between classical binary logic and the realities of uncertain information, making it a valuable tool for developing sophisticated trading strategies and analytical models.
Library "TUF_LOGIC"
3VL Implementation (TUF stands for True, Uncertain, False.)
method validate(self)
Ensures a valid trilean variable. This works by clamping the variable to the range associated with the trilean type.
Namespace types: tri
Parameters:
self (tri)
Returns: Validated trilean object.
method to_bool(self)
Converts a trilean object into a boolean object. True -> True, Uncertain -> na, False -> False.
Namespace types: tri
Parameters:
self (tri)
Returns: A boolean variable.
method NOT(self)
Negates the trilean object. True -> False, Uncertain -> Uncertain, False -> True
Namespace types: tri
Parameters:
self (tri)
Returns: Negated trilean object.
method AND(self, comparator)
Logical AND operation for trilean objects.
Namespace types: tri
Parameters:
self (tri) : The first trilean object.
comparator (tri) : The second trilean object to compare with.
Returns: `tri` Result of the AND operation as a trilean object.
method OR(self, comparator)
Logical OR operation for trilean objects.
Namespace types: tri
Parameters:
self (tri) : The first trilean object.
comparator (tri) : The second trilean object to compare with.
Returns: `tri` Result of the OR operation as a trilean object.
method EQUALITY(self, comparator)
Logical EQUALITY operation for trilean objects.
Namespace types: tri
Parameters:
self (tri) : The first trilean object.
comparator (tri) : The second trilean object to compare with.
Returns: `tri` Result of the EQUALITY operation as a trilean object, True if both are equal, False otherwise.
method XOR(self, comparator)
Logical XOR (Exclusive OR) operation for trilean objects.
Namespace types: tri
Parameters:
self (tri) : The first trilean object.
comparator (tri) : The second trilean object to compare with.
Returns: `tri` Result of the XOR operation as a trilean object.
method IMP_K(self, comparator)
Material implication using Kleene's logic for trilean objects.
Namespace types: tri
Parameters:
self (tri) : The antecedent trilean object.
comparator (tri) : The consequent trilean object.
Returns: `tri` Result of the implication operation as a trilean object.
method IMP_L(self, comparator)
Logical implication using Łukasiewicz's logic for trilean objects.
Namespace types: tri
Parameters:
self (tri) : The antecedent trilean object.
comparator (tri) : The consequent trilean object.
Returns: `tri` Result of the implication operation as a trilean object.
method IMP_RM3(self, comparator)
Logical implication using RM3 logic for trilean objects.
Namespace types: tri
Parameters:
self (tri) : The antecedent trilean object.
comparator (tri) : The consequent trilean object.
Returns: `tri` Result of the RM3 implication as a trilean object.
method MA(self)
Evaluates to True if the trilean object is either True or Uncertain, False otherwise.
Namespace types: tri
Parameters:
self (tri) : The trilean object to evaluate.
Returns: `tri` Result of the operation as a trilean object.
method LA(self)
Evaluates to True if the trilean object is True, False otherwise.
Namespace types: tri
Parameters:
self (tri) : The trilean object to evaluate.
Returns: `tri` Result of the operation as a trilean object.
method IA(self)
Evaluates to True if the trilean object is Uncertain, False otherwise.
Namespace types: tri
Parameters:
self (tri) : The trilean object to evaluate.
Returns: `tri` Result of the operation as a trilean object.
UNANIMOUS(self, comparator)
Evaluates the unanimity between two trilean values.
Parameters:
self (tri) : The first trilean value.
comparator (tri) : The second trilean value.
Returns: `tri` Returns True if both values are True, False if both are False, and Uncertain otherwise.
method UNANIMOUS(self)
Evaluates the unanimity among an array of trilean values.
Namespace types: array
Parameters:
self (array) : The array of trilean values.
Returns: `tri` Returns True if all values are True, False if all are False, and Uncertain otherwise.
tri
Three Value Logic (T.U.F.), or trilean. Can be True (1), Uncertain (0), or False (-1).
Fields:
v (series int) : Value of the trilean variable. Can be True (1), Uncertain (0), or False (-1).
MATH
DynamicFunctionsLibrary "DynamicFunctions"
Custom Dynamic functions that allow an adaptive calculation beginning from the first bar
RoC(src, period)
Dynamic RoC
Parameters:
src (float) : and period
Custom function to calculate the actual period considering non-na source values
period (int)
dynamicMedian(src, length)
Dynamic Median
Parameters:
src (float) : and length
length (int)
kernelRegression(src, bandwidth, kernel_type)
Dynamic Kernel Regression Calculation Uses either of the following inputs for kernel_type: Epanechnikov Logistic Wave
Parameters:
src (float)
bandwidth (int)
kernel_type (string)
waveCalculation(source, bandwidth, width)
Use together with kernelRegression function to get chart applicable band
Parameters:
source (float)
bandwidth (int)
width (float)
Rsi(src, length)
Dynamic RSI function
Parameters:
src (float)
length (int)
dynamicStdev(src, period)
Dynamic SD function
Parameters:
src (float)
period (int)
stdv_bands(src, length, mult)
Dynamic SD Bands
Parameters:
src (float)
length (int)
mult (float)
Returns: Basis, Positive SD, Negative SD
Adx(dilen, adxlen)
Dynamic ADX
Parameters:
dilen (int)
adxlen (int)
Returns: adx
Atr(length)
Dynamic ATR
Parameters:
length (int)
Returns: ATR
Macd(source, fastLength, slowLength, signalSmoothing)
Dynamic MACD
Parameters:
source (float)
fastLength (int)
slowLength (int)
signalSmoothing (int)
Returns: macdLine, signalLine, histogram

footprint_logicLibrary "footprint_logic"
Footprint logic getting internal buy/sell volume, inbalance...
get_buy_sell_volume(previos_close, tick_close, tick_high, tick_low, row_size, global_inbalance_high, global_inbalance_low, global_line_inbalance_high, global_line_inbalance_low, footprint_price, footprint_volume, tick_close_prev, level_group, tick_vol, stacked_input, inbalance_percent)
get global_buy_vol,global_sell_vol,level_volume_buy,level_volume_sell,level_inbalance_buy,level_inbalance_sell
Parameters:
previos_close (string)
tick_close (array)
tick_high (array)
tick_low (array)
row_size (float)
global_inbalance_high (array)
global_inbalance_low (array)
global_line_inbalance_high (array)
global_line_inbalance_low (array)
footprint_price (array)
footprint_volume (array)
tick_close_prev (array)
level_group (array)
tick_vol (array)
stacked_input (int)
inbalance_percent (int)
Returns: : float global_buy_vol,float global_sell_vol, level_volume_buy, level_volume_sell,map.new level_inbalance_buy,map.new level_inbalance_sell

Kernels©2024, GoemonYae; copied from @jdehorty's "KernelFunctions" on 2024-03-09 to ensure future dependency compatibility. Will also add more functions to this script.
Library "KernelFunctions"
This library provides non-repainting kernel functions for Nadaraya-Watson estimator implementations. This allows for easy substition/comparison of different kernel functions for one another in indicators. Furthermore, kernels can easily be combined with other kernels to create newer, more customized kernels.
rationalQuadratic(_src, _lookback, _relativeWeight, startAtBar)
Rational Quadratic Kernel - An infinite sum of Gaussian Kernels of different length scales.
Parameters:
_src (float) : The source series.
_lookback (simple int) : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_relativeWeight (simple float) : Relative weighting of time frames. Smaller values resut in a more stretched out curve and larger values will result in a more wiggly curve. As this value approaches zero, the longer time frames will exert more influence on the estimation. As this value approaches infinity, the behavior of the Rational Quadratic Kernel will become identical to the Gaussian kernel.
startAtBar (simple int)
Returns: yhat The estimated values according to the Rational Quadratic Kernel.
gaussian(_src, _lookback, startAtBar)
Gaussian Kernel - A weighted average of the source series. The weights are determined by the Radial Basis Function (RBF).
Parameters:
_src (float) : The source series.
_lookback (simple int) : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
startAtBar (simple int)
Returns: yhat The estimated values according to the Gaussian Kernel.
periodic(_src, _lookback, _period, startAtBar)
Periodic Kernel - The periodic kernel (derived by David Mackay) allows one to model functions which repeat themselves exactly.
Parameters:
_src (float) : The source series.
_lookback (simple int) : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_period (simple int) : The distance between repititions of the function.
startAtBar (simple int)
Returns: yhat The estimated values according to the Periodic Kernel.
locallyPeriodic(_src, _lookback, _period, startAtBar)
Locally Periodic Kernel - The locally periodic kernel is a periodic function that slowly varies with time. It is the product of the Periodic Kernel and the Gaussian Kernel.
Parameters:
_src (float) : The source series.
_lookback (simple int) : The number of bars used for the estimation. This is a sliding value that represents the most recent historical bars.
_period (simple int) : The distance between repititions of the function.
startAtBar (simple int)
Returns: yhat The estimated values according to the Locally Periodic Kernel.
LTI_FiltersLinear Time-Invariant (LTI) filters are fundamental tools in signal processing that operate with consistent behavior over time and linearly respond to input signals. They are crucial for analyzing and manipulating signals in various applications, ensuring the output signal's integrity is maintained regardless of when an input is applied or its magnitude. The Windowed Sinc filter is a specific type of LTI filter designed for digital signal processing. It employs a Sinc function, ideal for low-pass filtering, truncated and shaped within a finite window to make it practically implementable. This process involves multiplying the Sinc function by a window function, which tapers off towards the ends, making the filter finite and suitable for digital applications. Windowed Sinc filters are particularly effective for tasks like data smoothing and removing unwanted frequency components, balancing between sharp cutoff characteristics and minimal distortion. The efficiency of Windowed Sinc filters in digital signal processing lies in their adept use of linear algebra, particularly in the convolution process, which combines input data with filter coefficients to produce the desired output. This mathematical foundation allows for precise control over the filtering process, optimizing the balance between filtering performance and computational efficiency. By leveraging linear algebra techniques such as matrix multiplication and Toeplitz matrices, these filters can efficiently handle large datasets and complex filtering tasks, making them invaluable in applications requiring high precision and speed, such as audio processing, financial signal analysis, and image restoration.
Library "LTI_Filters"
offset(length, enable)
Calculates the time offset required for aligning the output of a filter with its input, based on the filter's length. This is useful for centered filters where the output is naturally shifted due to the filter's operation.
Parameters:
length (simple int) : The length of the filter.
enable (simple bool) : A boolean flag to enable or dissable the offset calculation.
Returns: The calculated offset if enabled; otherwise, returns 0.
lti_filter(filter_type, source, length, prefilter, centered, fc, window_type)
General-purpose Linear Time-Invariant (LTI) filter function that can apply various filter types to a data series. Can be used to apply a variety of LTI filters with different characteristics to financial data series or other time series data.
Parameters:
filter_type (simple string) : Specifies the type of filter. ("Sinc", "SMA", "WMA")
source (float) : The input data series to filter.
length (simple int) : The length of the filter.
prefilter (simple bool) : Boolean indicating whether to prefilter the input data.
centered (simple bool) : Determines whether the filter coefficients are centered.
fc (simple float) : Filter cutoff. Expressed like a length.
window_type (simple string) : Type of window function to apply. ("Hann", "Hamming", "Blackman", "Triangular", "Lanczos", "None")
Returns: The filtered data series.
lti_sma(source, length, prefilter)
Applies a Simple Moving Average (SMA) filter to the data series. Useful for smoothing data series to identify trends or for use as a component in more complex indicators.
Parameters:
source (float) : The input data series to filter.
length (simple int) : The length of the SMA filter.
prefilter (simple bool) : Boolean indicating whether to prefilter the input data.
Returns: The SMA-filtered data series.
lti_wma(source, length, prefilter, centered)
Applies a Weighted Moving Average (WMA) filter to a data series. Ideal for smoothing data with emphasis on more recent values, allowing for dynamic adjustments to the weighting scheme.
Parameters:
source (float) : The input data series to filter.
length (simple int) : The length of the WMA filter.
prefilter (simple bool) : Boolean indicating whether to prefilter the input data.
centered (simple bool) : Determines whether the filter coefficients are centered.
Returns: The WMA-filtered data series.
lti_sinc(source, length, prefilter, centered, fc, window_type)
Applies a Sinc filter to a data series, optionally using a window function. Particularly useful for signal processing tasks within financial analysis, such as smoothing or trend identification, with the ability to fine-tune filter characteristics.
Parameters:
source (float) : The input data series to filter.
length (simple int) : The length of the Sinc filter.
prefilter (simple bool) : Boolean indicating whether to prefilter the input data.
centered (simple bool) : Determines whether the filter coefficients are centered.
fc (simple float) : Filter cutoff. Expressed like a length.
window_type (simple string) : Type of window function to apply. ("Hann", "Hamming", "Blackman", "Triangular", "Lanczos", "None")
Returns: The Sinc-filtered data series.

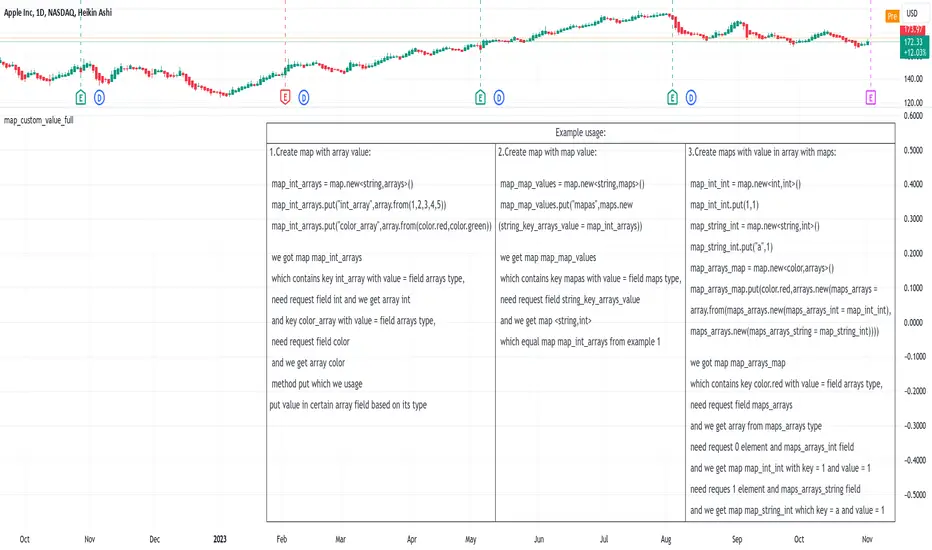
map_custom_value_fullLibrary "map_custom_value_full"
makes it possible to create:
1.map with array value:
for this purpose need:
1.create map with arrays type value
2.put your array in this map, overloaded put method itself will put the array based on the type into the required field
3.next you can get this array with help standard get function, by specifying the type field of your array
2.map with map value:
for this purpose need:
1.create map with maps type value
2.put your other map in how value in your based map, need you need to put it in the field corresponding to your map type
3.next you can get this map with help standard get function, by specifying the type field of your array
3.maps with value in array with maps:
for this purpose need:
1.create map with arrays type value
2.put as value maps_arrays fild with array from maps_arrays type fild which should already contain map of the type you need (there are not all map type fields here you can add a map of the required type by adding a corresponding field of map_arrays type.)
3.next you can get this array from map with help standard get function, by specifying the type field of your array
HT: Functions LibLibrary "Functions"
is_date_equal(date1, date2, time_zone)
Parameters:
date1 (int)
date2 (int)
time_zone (string)
is_date_equal(date1, date2_str, time_zone)
Parameters:
date1 (int)
date2_str (string)
time_zone (string)
is_date_between(date_, start_year, start_month, end_year, end_month, time_zone_)
Parameters:
date_ (int)
start_year (int)
start_month (int)
end_year (int)
end_month (int)
time_zone_ (string)
is_time_equal(time1, time2_str, time_zone)
Parameters:
time1 (int)
time2_str (string)
time_zone (string)
is_time_equal(time1, time2, time_zone)
Parameters:
time1 (int)
time2 (int)
time_zone (string)
is_time_between(time_, start_hour, start_minute, end_hour, end_minute, time_zone_)
Parameters:
time_ (int)
start_hour (int)
start_minute (int)
end_hour (int)
end_minute (int)
time_zone_ (string)
is_time_between(time_, start_time, end_time, time_zone_)
Parameters:
time_ (int)
start_time (string)
end_time (string)
time_zone_ (string)
is_close(value, level, ticks)
Parameters:
value (float)
level (float)
ticks (int)
is_inrange(value, lb, hb)
Parameters:
value (float)
lb (float)
hb (float)
is_above(value, level, ticks)
Parameters:
value (float)
level (float)
ticks (int)
is_below(value, level, ticks)
Parameters:
value (float)
level (float)
ticks (int)
NormalDistributionFunctionsLibrary "NormalDistributionFunctions"
The NormalDistributionFunctions library encompasses a comprehensive suite of statistical tools for financial market analysis. It provides functions to calculate essential statistical measures such as mean, standard deviation, skewness, and kurtosis, alongside advanced functionalities for computing the probability density function (PDF), cumulative distribution function (CDF), Z-score, and confidence intervals. This library is designed to assist in the assessment of market volatility, distribution characteristics of asset returns, and risk management calculations, making it an invaluable resource for traders and financial analysts.
meanAndStdDev(source, length)
Calculates and returns the mean and standard deviation for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
length (int) : int: The lookback period for the calculation.
Returns: Returns an array where the first element is the mean and the second element is the standard deviation of the data series for the given period.
skewness(source, mean, stdDev, length)
Calculates and returns skewness for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
length (int) : int: The lookback period for the calculation.
Returns: Returns skewness value
kurtosis(source, mean, stdDev, length)
Calculates and returns kurtosis for a given data series over a specified period.
Parameters:
source (float) : float: The data series to analyze.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
length (int) : int: The lookback period for the calculation.
Returns: Returns kurtosis value
pdf(x, mean, stdDev)
pdf: Calculates the probability density function for a given value within a normal distribution.
Parameters:
x (float) : float: The value to evaluate the PDF at.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
Returns: Returns the probability density function value for x.
cdf(x, mean, stdDev)
cdf: Calculates the cumulative distribution function for a given value within a normal distribution.
Parameters:
x (float) : float: The value to evaluate the CDF at.
mean (float) : float: The mean of the distribution.
stdDev (float) : float: The standard deviation of the distribution.
Returns: Returns the cumulative distribution function value for x.
confidenceInterval(mean, stdDev, size, confidenceLevel)
Calculates the confidence interval for a data series mean.
Parameters:
mean (float) : float: The mean of the data series.
stdDev (float) : float: The standard deviation of the data series.
size (int) : int: The sample size.
confidenceLevel (float) : float: The confidence level (e.g., 0.95 for 95% confidence).
Returns: Returns the lower and upper bounds of the confidence interval.

aproxLibrary "aprox"
It's a library of the aproximations of a price or Series float it uses Fourier transform and
Euler's Theoreum for Homogenus White noice operations. Calling functions without source value it automatically take close as the default source value.
Copy this indicator to see how each approximations interact between each other.
import Celje_2300/aprox/1 as aprox
//@version=5
indicator("Close Price with Aproximations", shorttitle="Close and Aproximations", overlay=false)
// Sample input data (replace this with your own data)
inputData = close
// Plot Close Price
plot(inputData, color=color.blue, title="Close Price")
dtf32_result = aprox.DTF32()
plot(dtf32_result, color=color.green, title="DTF32 Aproximation")
fft_result = aprox.FFT()
plot(fft_result, color=color.red, title="DTF32 Aproximation")
wavelet_result = aprox.Wavelet()
plot(wavelet_result, color=color.orange, title="Wavelet Aproximation")
wavelet_std_result = aprox.Wavelet_std()
plot(wavelet_std_result, color=color.yellow, title="Wavelet_std Aproximation")
DFT3(xval, _dir)
Parameters:
xval (float)
_dir (int)
//@version=5
import Celje_2300/aprox/1 as aprox
indicator("Example - DFT3", shorttitle="DFT3 Example", overlay=true)
// Sample input data (replace this with your own data)
inputData = close
// Apply DFT3
result = aprox.DFT3(inputData, 2)
// Plot the result
plot(result, color=color.blue, title="DFT3 Result")
DFT2(xval, _dir)
Parameters:
xval (float)
_dir (int)
//@version=5
import Celje_2300/aprox/1 as aprox
indicator("Example - DFT2", shorttitle="DFT2 Example", overlay=true)
// Sample input data (replace this with your own data)
inputData = close
// Apply DFT2
result = aprox.DFT2(inputData, inputData, 1)
// Plot the result
plot(result, color=color.green, title="DFT2 Result")
//@version=5
import Celje_2300/aprox/1 as aprox
indicator("Example - DFT2", shorttitle="DFT2 Example", overlay=true)
// Sample input data (replace this with your own data)
inputData = close
// Apply DFT2
result = aprox.DFT2(inputData, 1)
// Plot the result
plot(result, color=color.green, title="DFT2 Result")
FFT(xval)
FFT: Fast Fourier Transform
Parameters:
xval (float)
Returns: Aproxiated source value
//@version=5
import Celje_2300/aprox/1 as aprox
indicator("Example - FFT", shorttitle="FFT Example", overlay=true)
// Sample input data (replace this with your own data)
inputData = close
// Apply FFT
result = aprox.FFT(inputData)
// Plot the result
plot(result, color=color.red, title="FFT Result")
DTF32(xval)
DTF32: Combined Discrete Fourier Transforms
Parameters:
xval (float)
Returns: Aproxiated source value
//@version=5
import Celje_2300/aprox/1 as aprox
indicator("Example - DTF32", shorttitle="DTF32 Example", overlay=true)
// Sample input data (replace this with your own data)
inputData = close
// Apply DTF32
result = aprox.DTF32(inputData)
// Plot the result
plot(result, color=color.purple, title="DTF32 Result")
whitenoise(indic_, _devided, minEmaLength, maxEmaLength, src)
whitenoise: Ehler's Universal Oscillator with White Noise, without extra aproximated src
Parameters:
indic_ (float)
_devided (int)
minEmaLength (int)
maxEmaLength (int)
src (float)
Returns: Smoothed indicator value
//@version=5
import Celje_2300/aprox/1 as aprox
indicator("Example - whitenoise", shorttitle="whitenoise Example", overlay=true)
// Sample input data (replace this with your own data)
inputData = close
// Apply whitenoise
result = aprox.whitenoise(aprox.FFT(inputData))
// Plot the result
plot(result, color=color.orange, title="whitenoise Result")
whitenoise(indic_, dft1, _devided, minEmaLength, maxEmaLength, src)
whitenoise: Ehler's Universal Oscillator with White Noise and DFT1
Parameters:
indic_ (float)
dft1 (float)
_devided (int)
minEmaLength (int)
maxEmaLength (int)
src (float)
Returns: Smoothed indicator value
//@version=5
import Celje_2300/aprox/1 as aprox
indicator("Example - whitenoise with DFT1", shorttitle="whitenoise-DFT1 Example", overlay=true)
// Sample input data (replace this with your own data)
inputData = close
// Apply whitenoise with DFT1
result = aprox.whitenoise(inputData, aprox.DFT1(inputData))
// Plot the result
plot(result, color=color.yellow, title="whitenoise-DFT1 Result")
smooth(dft1, indic__, _devided, minEmaLength, maxEmaLength, src)
smooth: Smoothing source value with help of indicator series and aproximated source value
Parameters:
dft1 (float)
indic__ (float)
_devided (int)
minEmaLength (int)
maxEmaLength (int)
src (float)
Returns: Smoothed source series
//@version=5
import Celje_2300/aprox/1 as aprox
indicator("Example - smooth", shorttitle="smooth Example", overlay=true)
// Sample input data (replace this with your own data)
inputData = close
// Apply smooth
result = aprox.smooth(inputData, aprox.FFT(inputData))
// Plot the result
plot(result, color=color.gray, title="smooth Result")
smooth(indic__, _devided, minEmaLength, maxEmaLength, src)
smooth: Smoothing source value with help of indicator series
Parameters:
indic__ (float)
_devided (int)
minEmaLength (int)
maxEmaLength (int)
src (float)
Returns: Smoothed source series
//@version=5
import Celje_2300/aprox/1 as aprox
indicator("Example - smooth without DFT1", shorttitle="smooth-NoDFT1 Example", overlay=true)
// Sample input data (replace this with your own data)
inputData = close
// Apply smooth without DFT1
result = aprox.smooth(aprox.FFT(inputData))
// Plot the result
plot(result, color=color.teal, title="smooth-NoDFT1 Result")
vzo_ema(src, len)
vzo_ema: Volume Zone Oscillator with EMA smoothing
Parameters:
src (float)
len (simple int)
Returns: VZO value
vzo_sma(src, len)
vzo_sma: Volume Zone Oscillator with SMA smoothing
Parameters:
src (float)
len (int)
Returns: VZO value
vzo_wma(src, len)
vzo_wma: Volume Zone Oscillator with WMA smoothing
Parameters:
src (float)
len (int)
Returns: VZO value
alma2(series, windowsize, offset, sigma)
alma2: Arnaud Legoux Moving Average 2 accepts sigma as series float
Parameters:
series (float)
windowsize (int)
offset (float)
sigma (float)
Returns: ALMA value
Wavelet(src, len, offset, sigma)
Wavelet: Wavelet Transform
Parameters:
src (float)
len (int)
offset (simple float)
sigma (simple float)
Returns: Wavelet-transformed series
//@version=5
import Celje_2300/aprox/1 as aprox
indicator("Example - Wavelet", shorttitle="Wavelet Example", overlay=true)
// Sample input data (replace this with your own data)
inputData = close
// Apply Wavelet
result = aprox.Wavelet(inputData)
// Plot the result
plot(result, color=color.blue, title="Wavelet Result")
Wavelet_std(src, len, offset, mag)
Wavelet_std: Wavelet Transform with Standard Deviation
Parameters:
src (float)
len (int)
offset (float)
mag (int)
Returns: Wavelet-transformed series
//@version=5
import Celje_2300/aprox/1 as aprox
indicator("Example - Wavelet_std", shorttitle="Wavelet_std Example", overlay=true)
// Sample input data (replace this with your own data)
inputData = close
// Apply Wavelet_std
result = aprox.Wavelet_std(inputData)
// Plot the result
plot(result, color=color.green, title="Wavelet_std Result")
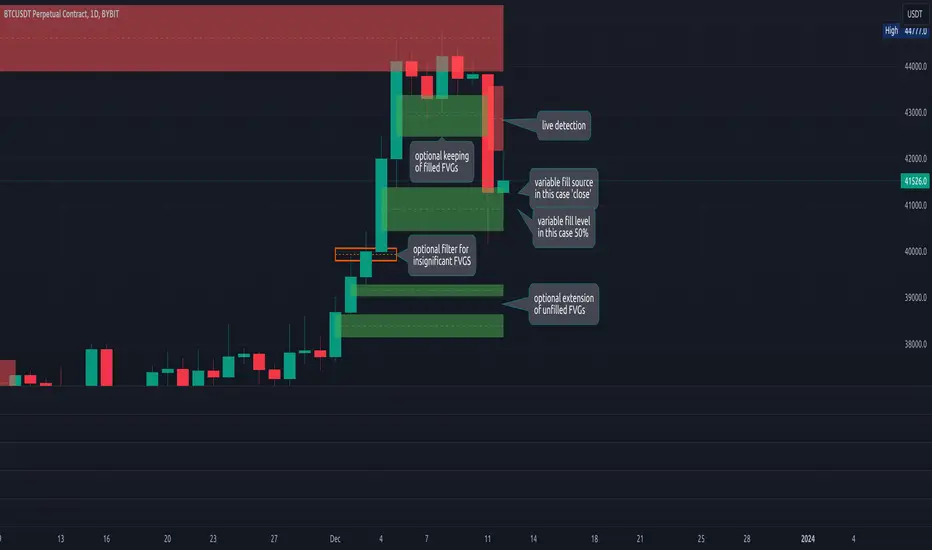
FVG Detector LibraryLibrary "FVG Detector Library"
🔵 Introduction
To save time and improve accuracy in your scripts for identifying Fair Value Gaps (FVGs), you can utilize this library. Apart from detecting and plotting FVGs, one of the most significant advantages of this script is the ability to filter FVGs, which you'll learn more about below. Additionally, the plotting of each FVG continues until either a new FVG occurs or the current FVG is mitigated.
🔵 Definition
Fair Value Gap (FVG) refers to a situation where three consecutive candlesticks do not overlap. Based on this definition, the minimum conditions for detecting a fair gap in the ascending scenario are that the minimum price of the last candlestick should be greater than the maximum price of the third candlestick, and in the descending scenario, the maximum price of the last candlestick should be smaller than the minimum price of the third candlestick.
If the filter is turned off, all FVGs that meet at least the minimum conditions are identified. This mode is simplistic and results in a high number of identified FVGs.
If the filter is turned on, you have four options to filter FVGs :
1. Very Aggressive : In addition to the initial condition, another condition is added. For ascending FVGs, the maximum price of the last candlestick should be greater than the maximum price of the middle candlestick. Similarly, for descending FVGs, the minimum price of the last candlestick should be smaller than the minimum price of the middle candlestick. In this mode, a very small number of FVGs are eliminated.
2. Aggressive : In addition to the conditions of the Very Aggressive mode, in this mode, the size of the middle candlestick should not be small. This mode eliminates more FVGs compared to the Very Aggressive mode.
3. Defensive : In addition to the conditions of the Very Aggressive mode, in this mode, the size of the middle candlestick should be relatively large, and most of it should consist of the body. Also, for identifying ascending FVGs, the second and third candlesticks must be positive, and for identifying descending FVGs, the second and third candlesticks must be negative. In this mode, a significant number of FVGs are eliminated, and the remaining FVGs have a decent quality.
4. Very Defensive : In addition to the conditions of the Defensive mode, the first and third candlesticks should not resemble very small-bodied doji candlesticks. In this mode, the majority of FVGs are filtered out, and the remaining ones are of higher quality.
By default, we recommend using the Defensive mode.
🔵 How to Use
🟣 Parameters
To utilize this library, you need to provide four input parameters to the function.
"FVGFilter" determines whether you wish to apply a filter on FVGs or not. The possible inputs for this parameter are "On" and "Off", provided as strings.
"FVGFilterType" determines the type of filter to be applied to the found FVGs. These filters include four modes: "Very Defensive", "Defensive", "Aggressive", and "Very Aggressive", respectively exhibiting decreasing sensitivity and indicating a higher number of Fair Value Gaps (FVG).
The parameter "ShowDeFVG" is a Boolean value defined as either "true" or "false". If this value is "true", FVGs are shown during the Bullish Trend; however, if it is "false", they are not displayed.
The parameter "ShowSuFVG" is a Boolean value defined as either "true" or "false". If this value is "true", FVGs are displayed during the Bearish Trend; however, if it is "false", they are not displayed.
FVGDetector(FVGFilter, FVGFilterType, ShowDeFVG, ShowSuFVG)
Parameters:
FVGFilter (string)
FVGFilterType (string)
ShowDeFVG (bool)
ShowSuFVG (bool)
🟣 Import Library
You can use the "FVG Detector" library in your script using the following expression:
import TFlab/FVGDetectorLibrary/1 as FVG
🟣 Input Parameters
The descriptions related to the input parameters were provided in the "Parameter" section. In this section, for your convenience, the code related to the inputs is also included, and you can copy and paste it into your script.
PFVGFilter = input.string('On', 'FVG Filter', )
PFVGFilterType = input.string('Defensive', 'FVG Filter Type', )
PShowDeFVG = input.bool(true, ' Show Demand FVG')
PShowSuFVG = input.bool(true, ' Show Supply FVG')
🟣 Call Function
You can copy the following code into your script to call the FVG function. This code is based on the naming conventions provided in the "Input Parameter" section, so if you want to use exactly this code, you should have similar parameter names or have copied the "Input Parameter" values.
FVG.FVGDetector(PFVGFilter, PFVGFilterType, PShowDeFVG, PShowSuFVG)

TimeSeriesRecurrencePlotLibrary "TimeSeriesRecurrencePlot"
In descriptive statistics and chaos theory, a recurrence plot (RP) is a plot showing, for each moment i i in time, the times at which the state of a dynamical system returns to the previous state at `i`, i.e., when the phase space trajectory visits roughly the same area in the phase space as at time `j`.
```
A recurrence plot (RP) is a graphical representation used in the analysis of time series data and dynamical systems. It visualizes recurring states or events over time by transforming the original time series into a binary matrix, where each element represents whether two consecutive points are above or below a specified threshold. The resulting Recurrence Plot Matrix reveals patterns, structures, and correlations within the data while providing insights into underlying mechanisms of complex systems.
```
~starling7b
___
Reference:
en.wikipedia.org
github.com
github.com
github.com
github.com
juliadynamics.github.io
distance_matrix(series1, series2, max_freq, norm)
Generate distance matrix between two series.
Parameters:
series1 (float) : Source series 1.
series2 (float) : Source series 2.
max_freq (int) : Maximum frequency to inpect or the size of the generated matrix.
norm (string) : Norm of the distance metric, default=`euclidean`, options=`euclidean`, `manhattan`, `max`.
Returns: Matrix with distance values.
method normalize_distance(M)
Normalizes a matrix within its Min-Max range.
Namespace types: matrix
Parameters:
M (matrix) : Source matrix.
Returns: Normalized matrix.
method threshold(M, threshold)
Updates the matrix with the condition `M(i,j) > threshold ? 1 : 0`.
Namespace types: matrix
Parameters:
M (matrix) : Source matrix.
threshold (float)
Returns: Cross matrix.
rolling_window(a, b, sample_size)
An experimental alternative method to plot a recurrence_plot.
Parameters:
a (array) : Array with data.
b (array) : Array with data.
sample_size (int)
Returns: Recurrence_plot matrix.

TimeSeriesGrammianAngularFieldLibrary "TimeSeriesGrammianAngularField"
provides Grammian angular field and associated utility functions.
___
Reference:
*Time Series Classification: A review of Algorithms and Implementations*.
www.researchgate.net
method normalize(data, a, b)
Normalize the series to a optional range, usualy within `(-1, 1)` or `(0, 1)`.
Namespace types: array
Parameters:
data (array) : Sample data to normalize.
a (float) : Minimum target range value, `default=-1.0`.
b (float) : Minimum target range value, `default= 1.0`.
Returns: Normalized array within new range.
___
Reference:
*Time Series Classification: A review of Algorithms and Implementations*.
normalize_series(source, length, a, b)
Normalize the series to a optional range, usualy within `(-1, 1)` or `(0, 1)`.\
*Note that this may provide a different result than the array version due to rolling range*.
Parameters:
source (float) : Series to normalize.
length (int) : Number of bars to sample the range.
a (float) : Minimum target range value, `default=-1.0`.
b (float) : Minimum target range value, `default= 1.0`.
Returns: Normalized series within new range.
method polar(data)
Turns a normalized sample array into polar coordinates.
Namespace types: array
Parameters:
data (array) : Sampled data values.
Returns: Converted array into polar coordinates.
polar_series(source)
Turns a normalized series into polar coordinates.
Parameters:
source (float) : Source series.
Returns: Converted series into polar coordinates.
method gasf(data)
Gramian Angular Summation Field *`GASF`*.
Namespace types: array
Parameters:
data (array) : Sampled data values.
Returns: Matrix with *`GASF`* values.
method gasf_id(data)
Trig. identity of Gramian Angular Summation Field *`GASF`*.
Namespace types: array
Parameters:
data (array) : Sampled data values.
Returns: Matrix with *`GASF`* values.
Reference:
*Time Series Classification: A review of Algorithms and Implementations*.
method gadf(data)
Gramian Angular Difference Field *`GADF`*.
Namespace types: array
Parameters:
data (array) : Sampled data values.
Returns: Matrix with *`GADF`* values.
method gadf_id(data)
Trig. identity of Gramian Angular Difference Field *`GADF`*.
Namespace types: array
Parameters:
data (array) : Sampled data values.
Returns: Matrix with *`GADF`* values.
Reference:
*Time Series Classification: A review of Algorithms and Implementations*.
LIB_TradeAssistLibrary "LIB_TradeAssist"
This library is a collection of assistence tools saving me the need to copy same code again and again in my various indicators and strategies.
Slop_Magnitude(val_now, val_older, mult_factor)
Calculate the slop magnetude betwen current price and an older price. Since the change is usually minimal, we multiply it by def value of 3000 to make it usable.You can optionally pass other multiply factor
Parameters:
val_now (float)
val_older (float)
mult_factor (float)
Returns: : Slop angle magnetude

series_collectionLibrary "series_collection"
A personal collection of commonly used series types like moving averages that are supported directly by
the pinescript library ('ALMA', 'DEMA', 'EMA', 'HMA', 'RMA', 'SMA', 'SWMA', 'VWMA', 'WMA'), highest and lowest source,
median and pivots. One single function (with overloads) that can be configured easily by the user input and can be
used as a core piece of functionality for many user cases. This library was created to abstract away and re-use this
commonly used functionality in my "Two MA Signal Indicator" script and the "Template Trailing Strategy" script. Both
of them use the "two_ma_logic" for defining entry and exit signals. While this piece of work does not contain any
novel mathematical expressions and just adds a convinient (and configurable) way to do things, I hope that might add
value to other scripts as well and future projects.
cust_series(length, seriesType, source)
cust_series - Calculate the custom series of the given source for the given length and type
Parameters:
length (simple int) : - The length of the custom series
seriesType (simple string) : - The type of the custom series
source (float) : - The source of the values
Returns: - The resulting value of the calculations of the custom series
cust_series(length, seriesType, source)
cust_series - Calculate the custom series of the given source for the given length and type
Parameters:
length (simple float) : - The length of the custom series (ceiled)
seriesType (simple string) : - The type of the custom series
source (float) : - The source of the values
Returns: - The resulting value of the calculations of the custom series
TimeSeriesClassificationActivationFunctionsLibrary "TimeSeriesClassificationActivationFunctions"
Provides some activation functions useful in time series classification.
___
reference:
github.com
method scale(dist, weights)
Activate values by a normalized scale.
Namespace types: map
Parameters:
dist (map) : Source distribution map.
weights (map) : Weights distribution map.
Returns: Normalized distribution map.
method softmax(dist, weights)
Activate values with a softmax algorithm.
Namespace types: map
Parameters:
dist (map) : Source distribution map.
weights (map) : Weights distribution map.
Returns: Normalized distribution map.
method argmax(dist, weights)
Activate values with a argmax algorithm.
Namespace types: map
Parameters:
dist (map) : Source distribution map.
weights (map) : Weights distribution map.
Returns: first key of argmax value of the transformed distribution.

MatrixScaleDownLibrary "MatrixScaleDown"
Provides a function to scale down a matrix into a smaller square format were its values are averaged to mantain matrix topology.
method scale_down(mat, size)
scale a matrix to a new smaller square size.
Namespace types: matrix
Parameters:
mat (matrix) : Source matrix.
size (int) : New matrix size.
Returns: New matrix with scaled down size. Source values will be averaged together.

lib_fvgLibrary "lib_fvg"
further expansion of my object oriented library toolkit. This lib detects Fair Value Gaps and returns them as objects.
Drawing them is a separate step so the lib can be used with securities. It also allows for usage of current/close price to detect fill/invalidation of a gap and to adjust the fill level dynamically. FVGs can be detected while forming and extended indefinitely while they're unfilled.
method draw(this)
Namespace types: FVG
Parameters:
this (FVG)
method draw(fvgs)
Namespace types: FVG
Parameters:
fvgs (FVG )
is_fvg(mode, precondition, filter_insignificant, filter_insignificant_atr_factor, live)
Parameters:
mode (int) : switch for detection 1 for bullish FVGs, -1 for bearish FVGs
precondition (bool) : allows for other confluences to block/enable detection
filter_insignificant (bool) : allows to ignore small gaps
filter_insignificant_atr_factor (float) : allows to adjust how small (compared to a 50 period ATR)
live (bool) : allows to detect FVGs while the third bar is forming -> will cause repainting
Returns: a tuple of (bar_index of gap bar, gap top, gap bottom)
create_fvg(mode, idx, top, btm, filled_at_pc, config)
Parameters:
mode (int) : switch for detection 1 for bullish FVGs, -1 for bearish FVGs
idx (int) : the bar_index of the FVG gap bar
top (float) : the top level of the FVG
btm (float) : the bottom level of the FVG
filled_at_pc (float) : the ratio (0-1) that the fill source needs to retrace into the gap to consider it filled/invalidated/ready for removal
config (FVGConfig) : the plot configuration/styles for the FVG
Returns: a new FVG object if there was a new FVG, else na
detect_fvg(mode, filled_at_pc, precondition, filter_insignificant, filter_insignificant_atr_factor, live, config)
Parameters:
mode (int) : switch for detection 1 for bullish FVGs, -1 for bearish FVGs
filled_at_pc (float)
precondition (bool) : allows for other confluences to block/enable detection
filter_insignificant (bool) : allows to ignore small gaps
filter_insignificant_atr_factor (float) : allows to adjust how small (compared to a 50 period ATR)
live (bool) : allows to detect FVGs while the third bar is forming -> will cause repainting
config (FVGConfig)
Returns: a new FVG object if there was a new FVG, else na
method update(this, fill_src)
Namespace types: FVG
Parameters:
this (FVG)
fill_src (float) : allows for usage of different fill source series, e.g. high for bearish FVGs, low vor bullish FVGs or close for both
method update(all, fill_src)
Namespace types: FVG
Parameters:
all (FVG )
fill_src (float)
method remove_filled(unfilled_fvgs)
Namespace types: FVG
Parameters:
unfilled_fvgs (FVG )
method delete(this)
Namespace types: FVG
Parameters:
this (FVG)
method delete_filled_fvgs_buffered(filled_fvgs, max_keep)
Namespace types: FVG
Parameters:
filled_fvgs (FVG )
max_keep (int) : the number of filled, latest FVGs to retain on the chart.
FVGConfig
Fields:
box_args (|robbatt/lib_plot_objects/36;BoxArgs|#OBJ)
line_args (|robbatt/lib_plot_objects/36;LineArgs|#OBJ)
box_show (series__bool)
line_show (series__bool)
keep_filled (series__bool)
extend (series__bool)
FVG
Fields:
config (|FVGConfig|#OBJ)
startbar (series__integer)
mode (series__integer)
top (series__float)
btm (series__float)
center (series__float)
size (series__float)
fill_size (series__float)
fill_lvl_target (series__float)
fill_lvl_current (series__float)
fillbar (series__integer)
filled (series__bool)
_fvg_box (|robbatt/lib_plot_objects/36;Box|#OBJ)
_fill_line (|robbatt/lib_plot_objects/36;Line|#OBJ)
AllTimeHighLowLibrary "AllTimeHighLow"
Provides functions calculating the all-time high/low of values.
hi(val)
Calculates the all-time high of a series.
Parameters:
val (float) : Series to use (`high` is used if no argument is supplied).
Returns: The all-time high for the series.
lo(val)
Calculates the all-time low of a series.
Parameters:
val (float) : Series to use (`low` is used if no argument is supplied).
Returns: The all-time low for the series.

VPQuantLibLibrary "VPQuantLib"
Misc of math, position size and consolidation detection functions that can be used accross various scripts.
isPercentAboveReference(current, percent, reference, or_equal)
Checks if the current value is bigger (or equal) with the provided percent value to the reference
Parameters:
current (float) : - what to check against the reference
percent (float) : - what is the percent to check for difference
reference (float) : - what to compare against
or_equal (bool) : - enables checking for bigger or equal
Returns: true if the current is percent bigger (or equal) to the reference
isPercentBelowReference(current, percent, reference, or_equal)
Checks if the current value is smaller (or equal) with the provided percent value to the reference
Parameters:
current (float) : - what to check against the reference
percent (float) : - what is the percent to check for difference
reference (float) : - what to compare against
or_equal (bool) : - enables checking for smaller or equal
Returns: true if the current is percent smaller (or equal) to the reference
isInRange(current, reference, min_percent, max_percent, below)
Checks if the current value is greater/smaller than the reference value within the provided percent range
Parameters:
current (float) : - what to check for being in range against the refenence
reference (float) : - what to compare against
min_percent (float) : - the min percent range border
max_percent (float) : - the max percent range border
below (bool) : - check if below or above the reference
@return true if the current is bigger/smaller than the reference withing the percent range provided
GetRiskBasedPositionSize(account_balance, equity_risk_perc, max_loss_per_share)
Calculates and returns the positins size based on risk of the equity
Parameters:
account_balance (float) : - total account balance
equity_risk_perc (int) : - percent of equity to risk in the trade
max_loss_per_share (float) : - maximum loss per share (in currency, not in %) that we're willing to loose (calc based on the entry_price-stop_loss_price)
@return number of shares to buy
CheckInRangeConsolidation(consolidation_period, allowed_consolidation_range, ref_high, ref_low, prev_bar_consolidaton, draw_consolidation_lines)
Checks if the current bar is in a consolidation range
Parameters:
consolidation_period (int) : - the number of bars to consider for consolidation range calculation
allowed_consolidation_range (int) : - the percentage range allowed for the current consolidation range to be considered valid
ref_high (float) : - the reference high value to use for consolidation range calculation
ref_low (float) : - the reference low value to use for consolidation range calculation
prev_bar_consolidaton (bool)
draw_consolidation_lines (bool) : - a boolean indicating if consolidation range lines should be drawn on the chart
@return a tuple of three values:
1. _curr_consolidation - a boolean indicating if the current bar is in consolidation range
2. _curr_consolidation_low - the current consolidation low value
3. _curr_consolidation_high - the current consolidation high value
FindBasicConsolidation(loopback_period, consolidation_length, ref_high, ref_low, draw_consolidation_lines)
Finds a basic consolidation areas, looking back 1000 bars to find the pivot of the trend and checks if the current bar is in consolidation area counting the
number of bars that have not broken the consolidation high/low levels
Parameters:
loopback_period (int) : - the number of bars to look back to determine the high/low watermark
consolidation_length (int) : - minimum number of bars required to establish a consolidation period
ref_high (float) : - user input for high (can be based on the bar or wicks)
ref_low (float) : - user input for high (can be based on the bar or wicks)
draw_consolidation_lines (bool) : - enable/disable drawing of the consolidation lines
Returns: _pivot_point - pivot point
commonThe "Pineify/common" library presents a specialized toolkit crafted to empower traders and script developers with state-of-the-art time manipulation functions on the TradingView platform. It is instead a foundational utility aimed at enriching your script's ability to process and interpret time-based data with unparalleled precision.
Key Features
String Splitter:
The 'str_split_into_two' function is a universal string handler that separates any given input into two distinct strings based on a specified delimiter. This function is especially useful in parsing time strings or any scenario where a string needs to be divided into logical parts efficiently.
Example:
= str_split_into_two("a:b", ":")
// a = "a"
// b = "b"
Time Parser:
With 'time_to_hour_minute', users can effortlessly convert a time string into numerical hours and minutes. This function is pivotal for those who need to exact specific time series data or wish to schedule their trades down to the minute.
Example:
= time_to_hour_minute("02:30")
// time_hour = 2
// time_minute = 30
Unix Time Converter
The 'time_range_to_unix_time' function transcends traditional boundaries by converting a given time range into Unix timestamp format. This integration of date, time, and timezone, accounts for a comprehensive approach, allowing scripts to make timed decisions, perform historical analyses, and account for international markets across different time zones.
Example:
// Support 'hhmm-hhmm' and 'hh:mm-hh:mm'
= time_range_to_unix_time("09:30-12:00")
Summary:
Each function is meticulously designed to minimize complexity and maximize versatility. Whether you are a programmer seeking to streamline your code, or a trader requiring precise timing for your strategies, our library provides the logical framework that aligns with your needs.
The "Pineify/common" library is the bridge between high-level time concepts and actionable trading insights. It serves a multitude of purposes – from crafting elegant time-based triggers to dissecting complex string data. Embrace the power of precision with "Pineify/common" and elevate your TradingView scripting experience to new heights.
Mad_FibonacciboxLibrary "Mad_Fibonaccibox"
This library is designed to create and manage multiple Fibonacci boxes, which are graphical representations based on the inputs.
-----------------
exports:
f_fib_calc(_Fibonacci_box, _itemnumber)
fibonacci calc.
@description This function block uses the levels and paramters set into the type_fibonacci_box(levels) and fills the corresponding array of prices.
Parameters:
_Fibonacci_box (type_Fibonacci_box )
_itemnumber (int)
Returns: returns a type_Fibonacci_box with the filled data
f_fib_draw(_Fibonacci_box, _itemnumber)
fibonacci draw.
@description This function block uses the levels, prices and paramters set into the type_fibonacci_box(levels) and draws the fib on the chart
Parameters:
_Fibonacci_box (type_Fibonacci_box )
_itemnumber (int)
Returns: returns lines labels and fills on the chart, no data returns
type_level
s for defining a lines and texts of a fibonacci box
Fields:
level (series float)
price (series float)
drawline (series bool)
linewidth (series int)
linetype (series string)
fiblinecolor (series color)
drawlabel (series string)
labeltext (series string)
textshift (series int)
fibtextcolor (series color)
fibtextsize (series string)
transp (series int)
type_fill
s for defining the fills of a fibonaccibox
Fields:
partner_A (series int)
partner_B (series int)
fill_color (series color)
transp (series int)
type_Fibonacci_box
s for defining a fibonacci box
Fields:
bottom_price (series float)
top_price (series float)
StartBar (series int)
StopBar (series int)
levels (type_level )
fills (type_fill )
ChartisLog (series bool)
fibreverse (series bool)
fibdrawreverse (series bool)
decimals_price (series int)
decimals_percent (series int)
drawlines (series bool)
drawlabels (series bool)
drawfills (series bool)
draw_biginfo (series bool)
biginfo_textshift (series int)
rangeinfo_location (series int)
rangeinfo_color (series color)
rangeinfo_textsize (series string)
line_array (line )
linefill_array (linefill )
label_array (label )

lib_mathLibrary "lib_math"
a collection of functions calculating without history operator to avoid max_bars_back errors
mean(value, reset)
Parameters:
value (float) : series to track
reset (bool) : flag to reset tracking
@return returns average/mean of value since last reset
vwap(value, reset)
Parameters:
value (float) : series to track
reset (bool) : flag to reset tracking
@return returns vwap of value and volume since last reset
variance(value, reset)
Parameters:
value (float) : series to track
reset (bool) : flag to reset tracking
@return returns variance of value since last reset
trend(value, reset)
Parameters:
value (float) : series to track
reset (bool) : flag to reset tracking
@return where slope is the trend direction, correlation is a measurement for how well the values fit to the trendline (positive means ), stddev is how far the values deviate from the trend, x1 would be the time where reset is true and x2 would be the current time
Price - TP/SLPrices
With this library, you can easily manage prices such as stop loss, take profit, calculate differences, prices from a lower timeframe, and get the order size and commission from the strategy properties tab.
Note that the order size and commission only work with strategies!
Usage
Take Profit & Stop Loss
var bool open_trade = false
open_trade := strategy.position_size != 0
bars_since_opened = strategy.opentrades > 0 ? bar_index - strategy.opentrades.entry_bar_index(strategy.opentrades - 1) + 1 : 0
// ############################################################
// # TAKE PROFIT
// ############################################################
take_profit = input.string(title='Take Profit', defval='OFF', options= , group='TAKE PROFIT')
take_profit_percentage = input.float(title='Take Profit (% or X)', defval=0, minval=0, step=0.1, group='TAKE PROFIT')
take_profit_bars = input.int(title='Take Profit Bars', defval=0, minval=0, step=1, group='TAKE PROFIT')
take_profit_indication = input.string(title='Take Profit Plot', defval='OFF', options= , group='TAKE PROFIT')
take_profit_color = input.color(title='Take Profit Color', defval=#26A69A, group='TAKE PROFIT')
take_profit_price = math.round_to_mintick(strategy.position_avg_price)
take_profit_plot = plot(take_profit == 'ON' and take_profit_indication == 'ON' and open_trade and bars_since_opened >= take_profit_bars and take_profit_percentage > 0 and nz(take_profit_price) ? take_profit_price : na, color=take_profit_color, style=plot.style_linebr, linewidth=1, title='TP', offset=0)
// ############################################################
// # STOP LOSS
// ############################################################
stop_loss = input.string(title='Stop Loss', defval='OFF', options= , group='STOP LOSS')
stop_loss_percentage = input.float(title='Stop Loss (% or X)', defval=0, minval=0, step=0.1, group='STOP LOSS')
stop_loss_bars = input.int(title='Stop Loss Bars', defval=0, minval=0, step=1, group='STOP LOSS')
stop_loss_indication = input.string(title='Stop Loss Plot', defval='OFF', options= , group='STOP LOSS')
stop_loss_color = input.color(title='Stop Loss Color', defval=#FF5252, group='STOP LOSS')
stop_loss_price = math.round_to_mintick(strategy.position_avg_price)
stop_loss_plot = plot(stop_loss == 'ON' and stop_loss_indication == 'ON' and open_trade and bars_since_opened >= stop_loss_bars and stop_loss_percentage > 0 and nz(stop_loss_price) ? stop_loss_price : na, color=stop_loss_color, style=plot.style_linebr, linewidth=1, title='SL', offset=0)
// ############################################################
// # STRATEGY
// ############################################################
var limit_price = 0.0
var stop_price = 0.0
limit_price := take_profit == 'ON' ? price.take_profit_price(take_profit_price, take_profit_percentage, take_profit_bars, bars_since_opened) : na
stop_price := stop_loss == 'ON' ? price.stop_loss_price(stop_loss_price, stop_loss_percentage, stop_loss_bars, bars_since_opened) : na
strategy.exit(id='TP/SL', comment='TP/SL', from_entry='LONG', limit=limit_price, stop=stop_price)
Calculate difference between 2 prices:
price.difference(close, close )
Get last price from lower timeframe:
price.ltf(request.security_lower_tf(ticker, '1', close))
Get the order size from the properties tab:
price.order_size()
Get the commission from the properties tab.
price.commission()

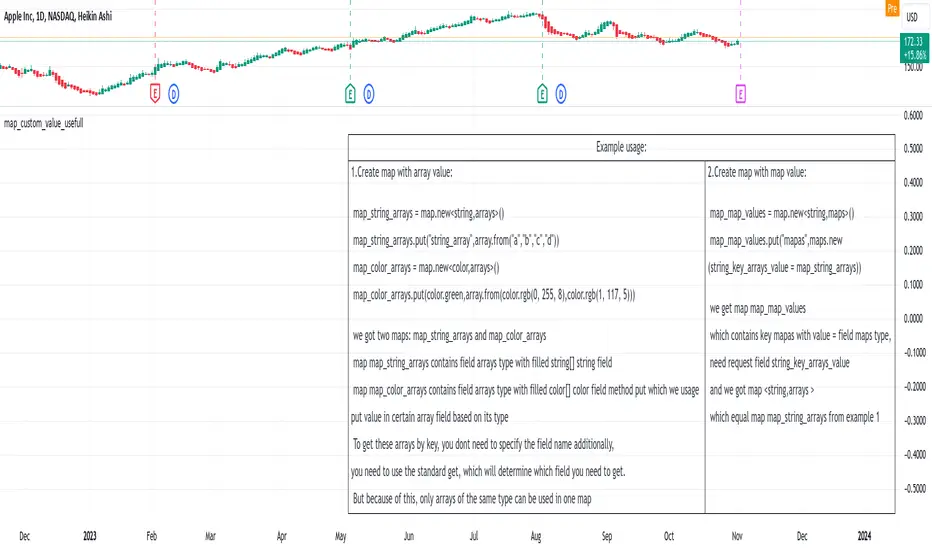
map_custom_value_usefullLibrary "map_custom_value_usefull"
makes it possible to create:
1.map with array value:
for this purpose need:
1.create map with arrays type value
2.put your array in this map, overloaded put method itself will put the array based on the type into the required field
3.next you can get this array with help standard get function, which will determine which field you need to get.(But because of this, only arrays of the same type can be used in one map)
2.map with map value:
for this purpose need:
1.create map with maps type value
2.put your other map in how value in your based map, need you need to put it in the field corresponding to your map type
3.next you can get this map with help standard get function.You need to specify a special field name here, because the get function cannot be overloaded without additional variables(